本篇文章来总结下业界有名的计算机深度学习方向的大佬们。引用最权威的资料来,学术界公认的h-index排名。所谓H-index,就是high citations,简单来说就是论文被引用的频次。
该系列文章摘抄于深入理解计算机系统第三章程序的机器级表示部分。书中部分章节介绍过于详细或基础,故不总结于此。只摘抄之前认识不深刻或者不理解的知识盲区。
微软于周五宣布,公司联合创始人兼技术顾问比尔·盖茨(Bill Gates)辞去微软董事会职务。
对于这一决定,盖茨表示:“伯克希尔公司和微软的领导层从未如此强大过,所以现在是采取这一步骤的时候了。”
斯坦福大学博士生与 Facebook 人工智能研究所研究工程师 Edward Z. Yang 是 PyTorch 开源项目的核心开发者之一。他在 5 月 14 日的 PyTorch 纽约聚会上做了一个有关 PyTorch 内部机制的演讲,本文是该演讲的长文章版本。
对大部分对CPU有一定了解的同学一定知道购买桌面级英特尔的CPU的时候,要看看CPU是i3、i5还是i7的,这大致决定了CPU的性能定位和价格。另外部分同学还会注意一下CPU带不带“K”。在我们的印象里带“K”后缀的CPU是能超频的,性能和价格也一定是比不带“K”的CPU要高出一截来的。这种粗广的判断方式不能算是错误的,但确实是不全面的。随着英特尔对自家新品的命名慢慢进入了一种匪夷所思的境界,这种情况正在变得越来越严重。
实验室一块GPU都没有怎么做深度学习?
如果让莱斯大学和英特尔的研究人员来回答,答案大概是:用CPU啊。
莱斯大学和英特尔的最新研究证明,无需专门的加速硬件(如GPU),也可以加速深度学习。
算法名为SLIDE。
研究人员称,SLIDE是第一个基于CPU的深度学习智能算法,并且,在具有大型全连接架构的行业级推荐数据集上,SLIDE训练深度神经网络的速度甚至超过了GPU。
代码已开源。
还记得2017年,微信红包收发总量达到460亿个,2019年,除夕到初五,8.23亿人收发微信红包。一觉醒来,微信群里各种红包,顿时觉得错过了几个亿,破解了红包的规律,是不是就可以发财了呢?
Horovod是Uber(优步)开源的又一个深度学习工,Horovod在2017年10月,Uber以Apache 2.0授权许可开源发布。Horovod是优步跨多台机器的分布式训练框架,现已加入开源计划LF Deep Learning Foundation。
Uber利用Horovod来支持自动驾驶汽车,欺诈检测和出行预测。该项目的贡献者包括亚马逊,IBM,英特尔和Nvidia。除了优步,阿里巴巴,亚马逊和Nvidia也在使用Horovod。Horovod项目可以与TensorFlow,Keras和PyTorch等流行框架一起使用。优步于上个月加入了Linux基金会,并加入了其他科技公司,如AT&T和诺基亚,他们出面支持LF Deep Learning Foundation开源项目。LF深度学习基金会成立于3月,旨在支持深度学习和机器学习的开源项目,并且是Linux基金会的一部分。在推出Acumos(用于训练和部署AI模型)和Acumos Marketplace(AI模型的开放式交易所)推出一个月后,Horovod正式推出。自该基金会启动以来,开展的其他项目包括机器学习平台Angel and Elastic Deep Learning,该项目旨在帮助云服务提供商利用TensorFlow等框架制作云集群服务。百度和腾讯分别于八月份加入这些项目,它们也是LF深度学习基金会的创始成员。
从一开始的Google搜索,到现在的聊天机器人、大数据风控、证券投资、智能医疗、自适应教育、推荐系统,无一不跟知识图谱相关。它在技术领域的热度也在逐年上升。本文以通俗易懂的方式来讲解知识图谱相关的知识、尤其对从零开始搭建知识图谱过程当中需要经历的步骤以及每个阶段需要考虑的问题都给予了比较详细的解释。对于读者,我们不要求有任何AI相关的背景知识。
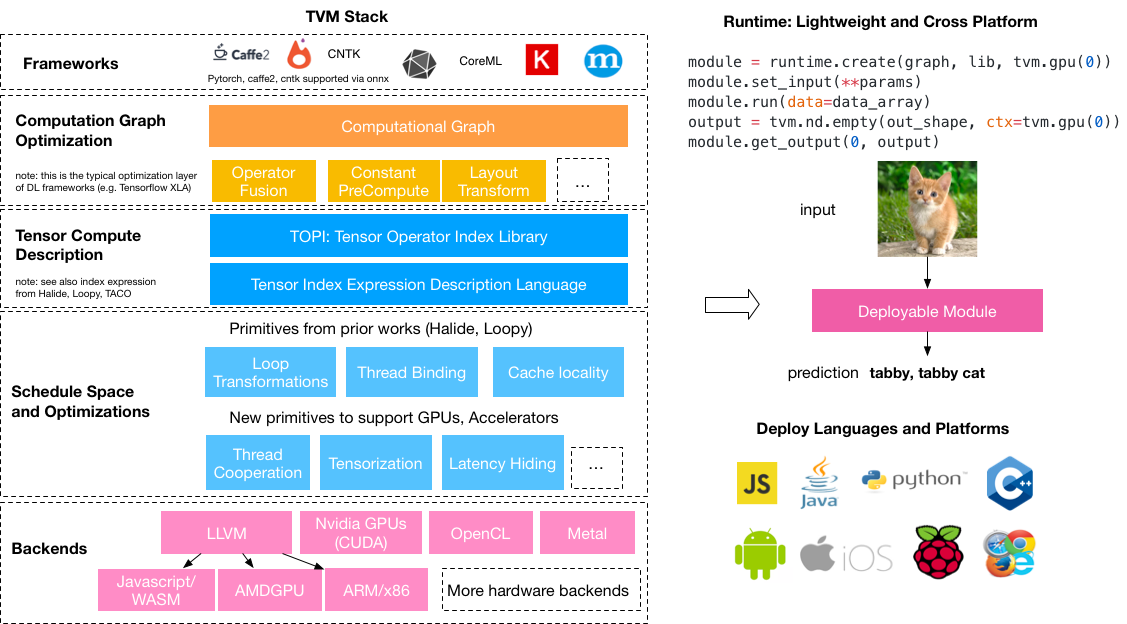
TVM可以称为许多工具集的集合,其中这些工具可以组合起来使用,来实现我们的一些神经网络的加速和部署功能。这也是为什么叫做TVM Stack了。TVM的使用途径很广,几乎可以支持市面上大部分的神经网络权重框架(ONNX、TF、Caffe2等),也几乎可以部署在任何的平台,例如Windows、Linux、Mac、ARM等等。
以下面一张图来形容一下,这张图来源于(https://tvm.ai/about):