
今天遇到了个很好玩的话题,怎么模(魔)糊(幻)打印Hello World。和平常第一次接触编程语言的Hello World不一样,平常一行就能完成的功能这里实现的能够异常复杂,并且生成了一堆看似乱码的字符,结果用python解析运行却能得到和Hello World一样的结果,原理我到现在还没完全搞明白,先做个记录后面慢慢理解吧。
我们为什么需要分布式,一方面是不得已而为之,例如
数据量太大,数据无法加载
模型太复杂,一个GPU放不下
或者我们也可以利用分布式提高我们的训练速度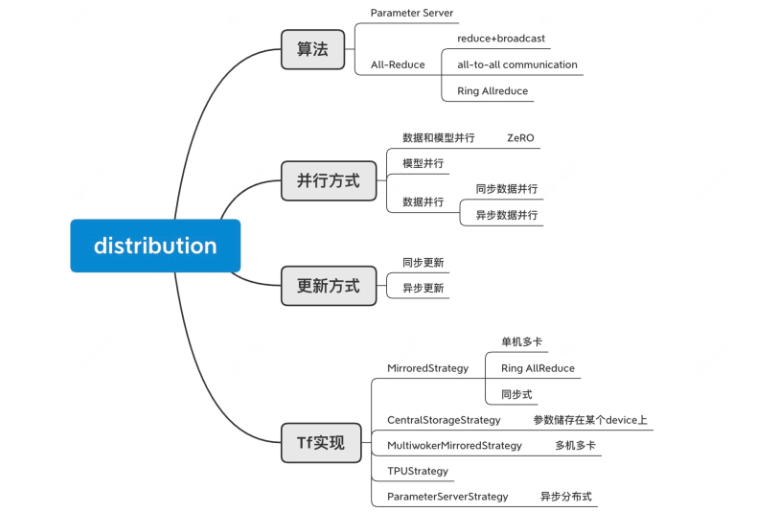
Performance of copy using different data types.
Got a performance issue on ATS when copy a continuous buffer of u16 data type. It is almost 2x slower than copy a buffer of same byte-length but using u32 data type. Similarly, copy of u8 is even slower. Below is a test case of copy a same buffer using different data type of u32/u16/u8.
MLPerf是业内首套衡量机器学习软硬件性能的通用基准,由图灵奖得主David Patterson联合谷歌和几所著名高校于2018年发起。
MLPerf 是AI芯片的一个基准测试,主要包括:Training 和Inference两个方面的性能测试。Training是于测量系统将模型训练到目标质量指标的速度;Inference是用于测试系统使用训练有素的模型处理输入和产生结果的速度。
MLPerf基准联盟现有83家成员,包括谷歌、英伟达、微软、Facebook、阿里巴巴等73家企业和斯坦福、哈佛、多伦多大学等10所高校
最近在分析不同的数据类型在深度学习过程中的应用,看CUDA的doc发现有篇文章是关于FP16数据类型对模型训练,达到节省带宽和内存的目的。基于数据模型的精度损失问题,需要分析模型参数的数值分布规律,做到量化和缩放操作避免损失模型精度。此文用来使用jupyter notebook 和matplotlib 可视化模型参数的具体过程。
如何衡量翻译的好坏? 机器翻译越接近专业的人工翻译,它就越好。 这是我们的提议背后的核心理念。 为了判断机器翻译的质量,可以根据一个数值指标来衡量其与一个或多个人工参考翻译的接近程度。 因此,我们的MT评估系统需要两个成分:
- 一个“翻译接近度”数值指标
- 一个高质量的人工参考翻译语料库
BLEU(Bilingual Evaluation Understudy),相信大家对这个评价指标的概念已经很熟悉,随便百度谷歌就有相关介绍。原论文为BLEU: a Method for Automatic Evaluation of Machine Translation,IBM出品。
本文通过一个例子详细介绍BLEU是如何计算以及NLTK nltk.align.bleu_score模块的源码。
首先祭出公式:
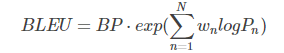
其中,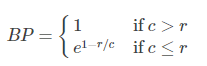
注意这里的BLEU值是针对一条翻译(一个样本)来说的。
最近需要验证一个bit_cast转换函数在GPU kernel里面的底层实现形式,之前一直猜想是Mov指令完成的,CPU端的代码往往通过gdb反汇编很容易看到每行代码对应个汇编语言,但是对于GPU的kernel,我却一直没有什么经验。刚好可以利用Intel最近准备release的OneAPI开发工具包,借助里面的gdb-oneapi和VTune工具来实现。本文就是记录这次踩坑过程。

This tutorial will discuss how to perform atomic operations in CUDA, which are often essential for many algorithms. Atomic operations are easy to use, and extremely useful in many applications. Atomic operations help avoid race conditions and can be used to make code simpler to write.
hook在维基百科中定义:钩子编程(hooking),也称作“挂钩”,是计算机程序设计术语,指通过拦截软件模块间的函数调用、消息传递、事件传递来修改或扩展操作系统、应用程序或其他软件组件的行为的各种技术。处理被拦截的函数调用、事件、消息的代码,被称为钩子(hook)。
Hook 是 PyTorch 中一个十分有用的特性。利用它,我们可以不必改变网络输入输出的结构,方便地获取、改变网络中间层变量的值和梯度。这个功能被广泛用于可视化神经网络中间层的 feature、gradient,从而诊断神经网络中可能出现的问题,分析网络有效性。本文将结合代码,由浅入深地介绍 pytorch 中 hook 的用法。本文分为三部分:
- Hook for Tensors :针对 Tensor 的 hook
- Hook for Modules:针对例如 nn.Conv2dnn.Linear等网络模块的 hook
- Guided Backpropagation:利用 Hook 实现的一段神经网络可视化代码
This post is not a tutorial on C++11 threads, but it uses them as the main threading mechanism to demonstrate its points. It starts with a basic example but then quickly veers off into the specialized area of thread affinities, hardware topologies and performance implications of hyperthreading. It does as much as feasible in portable C++, clearly marking the deviations into platform-specific calls for the really specialized stuff.