
实际上,性能优化一直都是大多数软件工程师头上的紧箍咒,甚至许多工作多年的资深工程师,有时也无法准确地分析出线上的很多性能问题。
性能分析问题为什么这么难呢?性能优化是个系统工具,常常牵一发而动全身。它涉及了从程序设计、算法分析、编程语言,再到系统、存储、网络等各种底层基础设施的方方面面。每一个组件都可能出现问题,甚至多个组件同时出现问题。毫无疑问,性能优化是软件系统中最有挑战的工作指引,也是最考验体现你综合能力的工作之一。该篇blog记录总结了倪朋飞老师在极客时间开设的《Linux性能优化实战》课程笔记。
如何理解“平均负载”
我们常用top或者uptime命令,来了解系统的负载情况。比如:
1 | zhiyuanhuang@ZhiyuandeMacBook-Pro blog % uptime |
分别表示当前时间、系统运行时间、正在登陆用户数。最后三个数字则分别表示过去1分钟、5分钟、15分钟的平均负载。但是平均负载究竟代表了什么?简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断转态的平均进程数,也就是平均活跃进程数,它和CPU使用率并没有直接关系。所谓可运行转态的进程,是指正在使用CPU或者正在等待CPU的进程,也即是我们用ps命令看到的R状态(running或Runnable)的的进程。不可中断的进程是指正处于内核状态关键流程中的进程,并且这些进程是不可打断的。比如最常见的是等待硬件设备的IO响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断的转态。否则会出现磁盘数据与进程数据不一致的情况。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
既然平均的是活跃进程数,那么最理想的情况就是每个CPU上面都刚好运行着一个进程,这个利用率最高。比如平均负载为2时,
- 在只有2个CPU的系统上,所有的CPU都刚好被完全占用。
- 在4个CPU的系统上,意味着有50%的空闲。
- 在只有1个CPU的系统中,有一半的进程竞争不到CPU。
平均负载多少最合适
要评判平均负载,首先你要知道系统有几个CPU,这个可以通过top命令或者从文件/proc/cpuinfo获取,比如:
1 | $ grep "model name" /proc/cpuinfo | wc -l |
从例子中可以看出,平均负载有三个数值,到底该参考哪一个呢?实际上都要看,三个不同时间间隔的平均值,其实给我们提供了,分析系统负载趋势的数据来源,让我们更加全面更立体了解目前的负载状况。一般来说,当平均负载高于CPU数量70%的时候就应该分析排查负载高的问题。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
平均负载与CPU使用率
现实中,经常会把平均负载和CPU使用率混淆。可能会困惑,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着CPU使用率高吗?回到平均负载的含义上来,平均负载是指在单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用的CPU的进程,还包括等待CPU和等待IO的进程。而CPU使用率,是单位时间内繁忙情况的统计,和平均负载并不一定完全对应。比如
- CPU密集型进程,使用大量CPU会导致平均进程负载升高,此时两者是一致的;
- IO密集型进程,等待IO也会导致平均负载升高,但CPU使用率不一定很高;
- 大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
案例分析
工具iostat、mpstat、pidstat。其中stress是一个Linux系统压力的测试工具,这里用作异常进程模拟平均负载升高的场景。而sysstat包括了常用的Linux性能工具,用来监控和分析系统的性能。mpstat是一个常用的多核CPU性能分析工具,用来实时查看每个CPU的性能指标,以及所有CPU的平均指标。pidstat是一个常用的进程性能分析工具,用来实时查看进程的CPU、内存、IO以及上下文切换等性能指标。每种场景都需要打开3个中端。
场景一: CPU密集型场景
终端1运行stress命令,模拟一个CPU使用率100%的场景:
1 | $ stress --cpu 1 --timeout 600 |
终端2运行uptime查看平均负载的变化情况:
1 | # -d 参数表示高亮显示变化的区域 |
终端3运行mpstat查看CPU使用率变化:
1 | # -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据 |
从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100%。到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询:
1 | # 间隔5秒后输出一组数据 |
从这里可以明显看到,stress 进程的 CPU 使用率为 100%。
场景二: IO密集型场景
首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync:
1 | $ stress -i 1 --timeout 600 |
在第二个终端运行 uptime 查看平均负载的变化情况:
1 | $ watch -d uptime |
第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
1 | # 显示所有CPU的指标,并在间隔5秒输出一组数据 |
从这里可以看到,1 分钟的平均负载会慢慢增加到 1.06,其中一个 CPU 的系统 CPU 使用率升高到了 23.87,而 iowait 高达 67.53%。这说明,平均负载的升高是由于 iowait 的升高。那么到底是哪个进程,导致 iowait 这么高呢?我们还是用 pidstat 来查询:
1 | # 间隔5秒后输出一组数据,-u表示CPU指标 |
可以发现,还是 stress 进程导致的。
场景三: 大量进程的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。我们还是使用 stress,但这次模拟的是 8 个进程:
1 | $ stress -c 8 --timeout 600 |
由于系统只有 2 个 CPU,明显比 8 个进程要少得多,因而,系统的 CPU 处于严重过载状态,平均负载高达 7.97:
1 | $ uptime |
接着再运行 pidstat 来看一下进程的情况:
1 | # 间隔5秒后输出一组数据 |
可以看出,8 个进程在争抢 2 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
经常说的CPU上下文切换是什么意思
进程在竞争CPU的时候并没有真正运行,为什么还会导致系统的负载升高?原因就是CPU上下文切换。
Linux是一个多任务操作系统,它支持远大于CPU数量的任务同时运行。这些任务实际上并不是真的在同时运行,而是因为在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。在每个任务开启钱,CPU都需要知道任务从哪里加载,从哪里开始运行。即需要系统事先帮助设置好CPU寄存器和程序计数器。
CPU寄存器,是CPU内资的容量小、但速度极快的内存。而程序计数器是用来存储CPU正在执行的指令位置、或者即将执行的下一条指令位置。它们都是CPU在运行任何任务钱,必须来来的环境,因此被叫做CPU上下文。
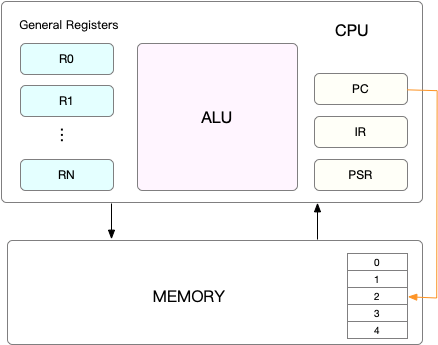
上下文切换就是把前一个任务的CPU上下文(CPU寄存器和程序计数器)保存起来,然后然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
有人说,CPU 上下文切换无非就是更新了 CPU 寄存器的值嘛,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的 CPU 性能呢?
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
进程上下文切换
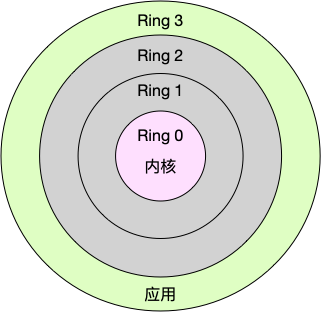
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
系统调用的过程有没有发生 CPU 上下文的切换呢?答案自然是肯定的。CPU寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
需要注意的是,系统调动过程中,并不会设计到虚拟内存等进程用户态的资源,也不会切换进程。
进程上下文切换,是指从一个进程切换到另一个进程。
而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。实际上,系统调用过程中,CPU的上下文切换还是无法避免的。那么,进程上下文切换和系统调用有什么区别呢?
首先,进程是由内核来管理和调度,进程的切换只能发生在内核态。所以进程的上下文切换不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。

根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是上一节中我们所讲的,导致平均负载升高的一个重要因素。
另外,我们知道, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。那么,进程在什么时候才会被调度到 CPU 上运行呢?
最容易想到的一个时机,就是进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。其实还有很多其他场景,也会触发进程调度,在这里我给你逐个梳理下。
其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
最后一个,发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
上下文切换引起的性能问题的幕后元凶往往就是以上几个场景。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
到这里你应该也发现了,虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。
vmstat
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。用法如下:
1 | # 每隔5秒输出1组数据 |
需要重点关注下面四列内容:
**cs (context switch)**是每秒上下文切换的次数
in (interrupt) 则是每秒中断的次数
**r (Running or Runnable)**是就绪队列的长度,也就是正在运行和等待CPU的进程数。
**b (Blocked)**则是处于不可中断睡眠状态的进程数。
vmstat 只给出了系统总体的上下文切换情况,要想查看每个进程的详细情况,就需要使用我们前面提到过的 pidstat 了。给它加上 -w 选项,你就可以查看每个进程上下文切换的情况了。
1 | # 每隔5秒输出1组数据 |
这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
这两个概念你一定要牢牢记住,因为它们意味着不同的性能问题:
所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
CPU哪性能优化的几个思路
CPU 的性能指标那么多,CPU性能分析工具也是一抓一大把,如果离开专栏,换成实际的工作场景,我又该观察什么指标、选择哪个性能工具呢?我们先来回顾下,描述 CPU 的性能指标都有哪些。
首先,最容易想到的应该是 CPU 使用率,这也是实际环境中最常见的一个性能指标。CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
软中断和硬中断的CPU使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
除了上面这些,还有在虚拟化环境中会用到的窃取CPU使用率(steal)和客户CPU使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
第二个比较容易想到的,应该是平均负载(Load Average),也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去15分钟的平均负载。理想情况下,平均负载等于逻辑CPU个数,这表示每个CPU都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
第三个,也是在专栏学习前你估计不太会注意到的,进程上下文切换,包括:
无法获取资源而导致的自愿上下文切换;
被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的CPU时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
除了上面几种,还有一个指标,CPU 缓存的命中率。由于 CPU 发展的速度远快于内存的发展CPU的处理速度就比内存的访问速度快得多。这样,CPU在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。
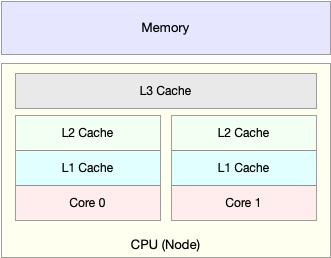
就像上面这张图显示的,CPU缓存的速度介于CPU和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中,L3则用在多核中。从L1到L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
现将CPU常用性能指标总结如下:
活学活用,把性能指标和性能工具联系起来第一个维度,从CPU的性能指标出发。也就是说,当你要查看某个性能指标时,要清楚知道哪些工具可以做到。
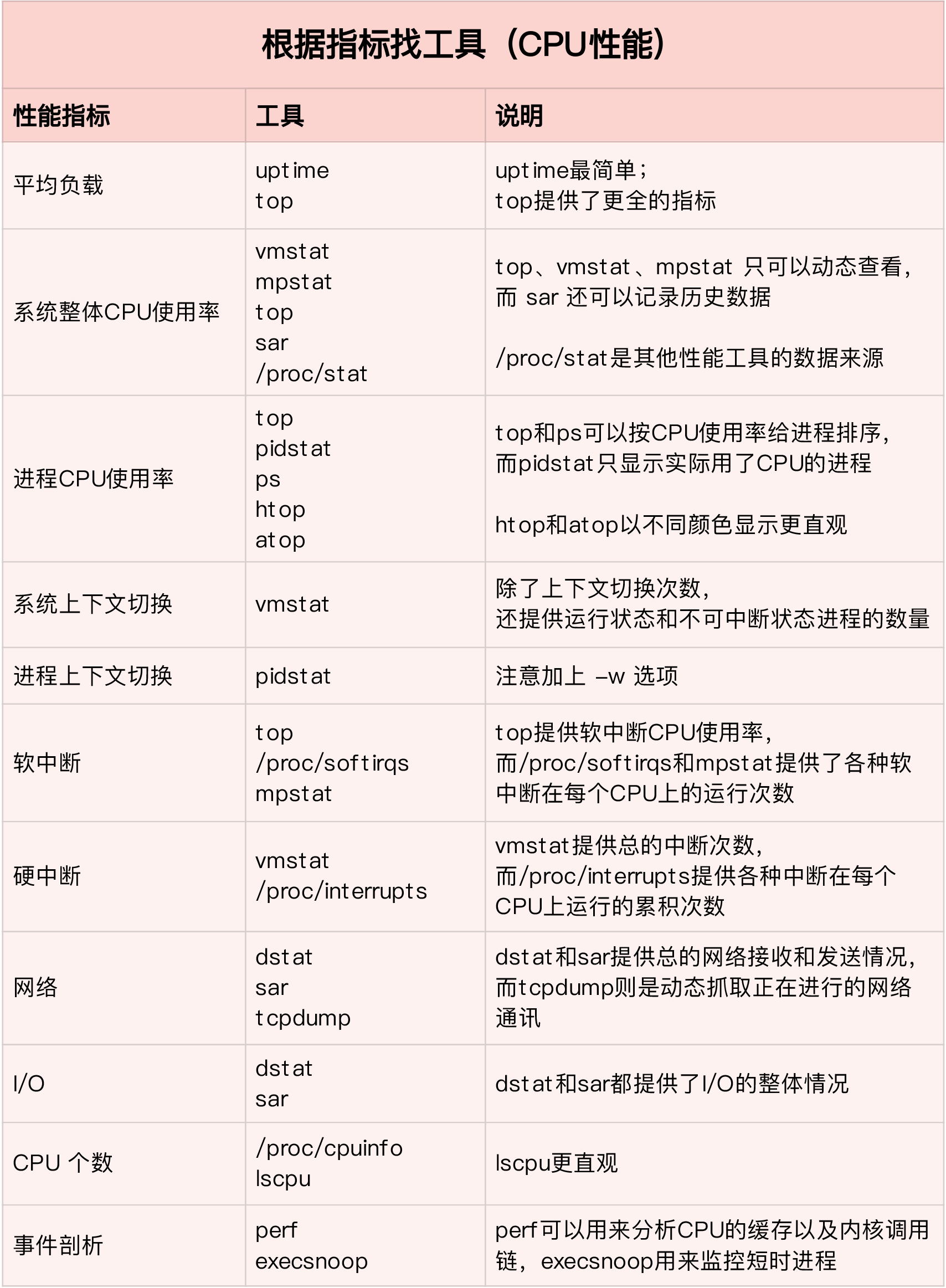
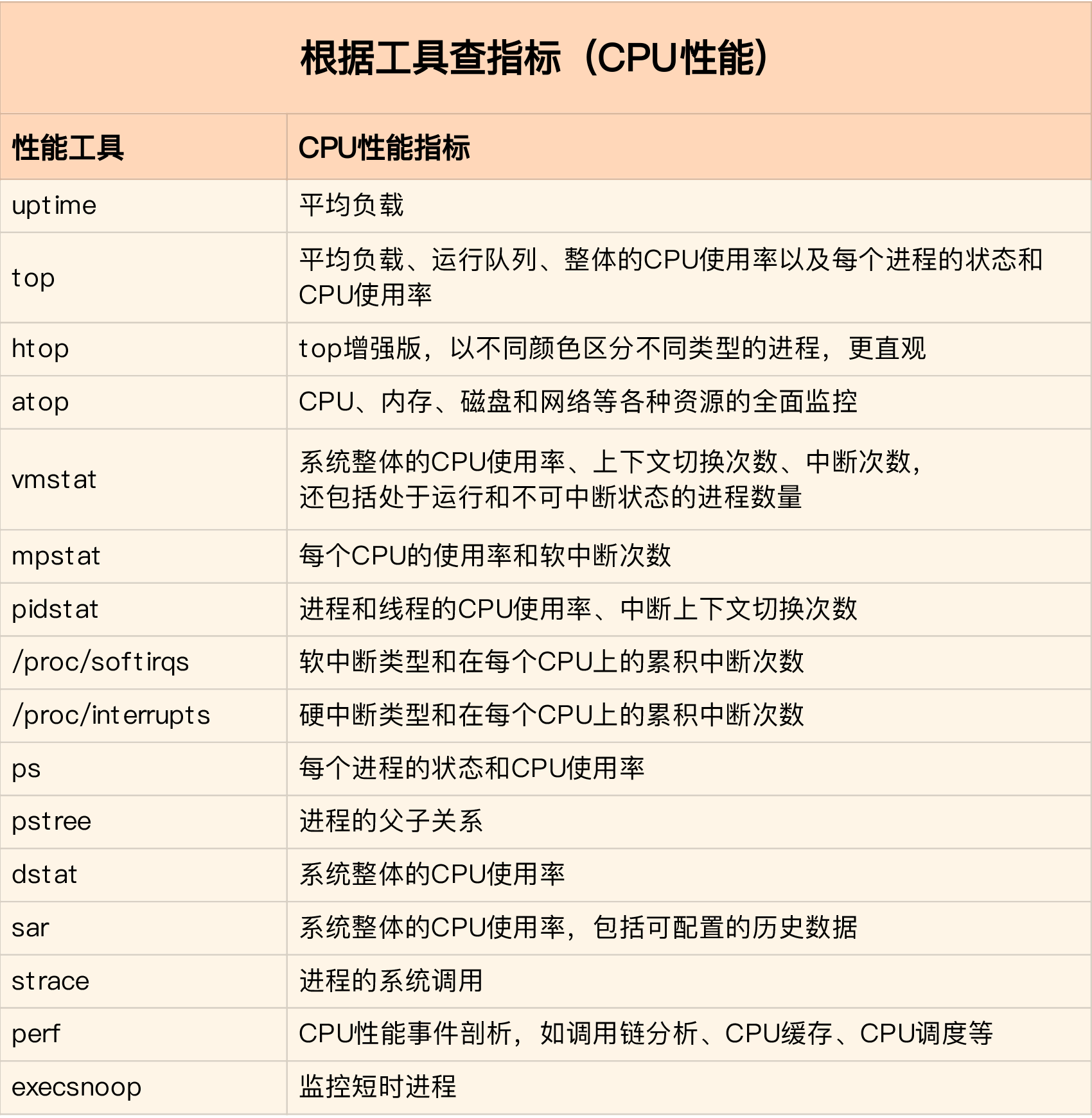
在实际生产环境中,我们通常都希望尽可能快地定位系统的瓶颈,然后尽可能快地优化性能,也就是要又快又准地解决性能问题。所以,为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如 top、vmstat 和 pidstat 。为什么是这三个工具呢?仔细看看下面这张图,你就清楚了。
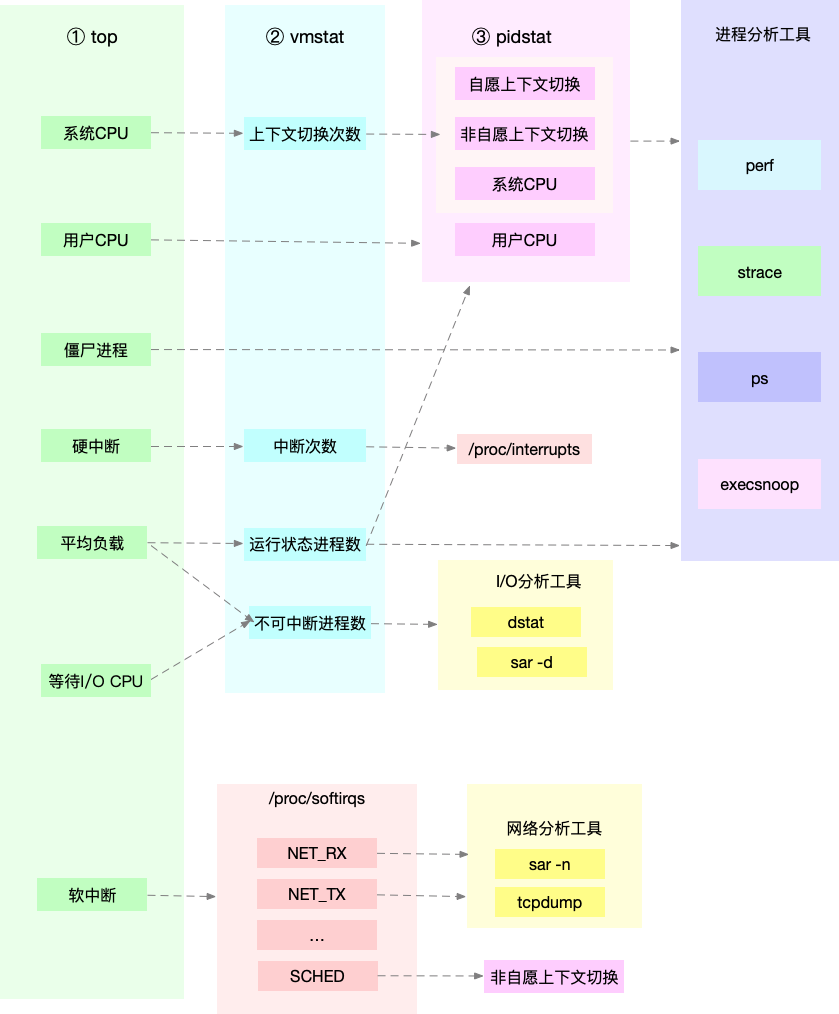
这张图里,列出了top、vmstat和pidstat分别提供的重要的CPU指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
- 从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
- 从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。

