
背景:
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点:
- 更少的模型体积,接近4倍的减少;
- 可以更快的计算,由于更少的内存访问和更快的int8计算,可以快2~4倍。
一个量化后的模型,其部分或者全部的tensor操作会使用int类型来计算,而不是使用量化之前的float类型。当然,量化还需要底层硬件支持,x86 CPU(支持AVX2)、ARM CPU、Google TPU、Nvidia Volta/Turing/Ampere、Qualcomm DSP这些主流硬件都对量化提供了支持。
PyTorch 1.1的时候开始添加torch.qint8 dtype、torch.quantize_linear转换函数来开始对量化提供有限的实验性支持。PyTorch 1.3开始正式支持量化,在可量化的Tensor之外,PyTorch开始支持CNN中最常见的operator的量化操作,包括:
- Tensor上的函数: view, clone, resize, slice, add, multiply, cat, mean, max, sort, topk;
- 常见的模块(在torch.nn.quantized中):Conv2d, Linear, Avgpool2d, AdaptiveAvgpool2d, MaxPool2d, AdaptiveMaxPool2d, Interpolate, Upsample;
- 为了量化后还维持更高准确率的合并操作(在torch.nn.intrinsic中):ConvReLU2d, ConvBnReLU2d, ConvBn2d,LinearReLU,add_relu。
在PyTorch 1.4的时候,PyTorch添加了nn.quantized.Conv3d,与此同时,torchvision 0.5开始提供量化版本的 ResNet、ResNext、MobileNetV2、GoogleNet、InceptionV3和ShuffleNetV2。到PyTorch 1.5的时候,QNNPACK添加了对dynamic quantization的支持,也就为量化版的LSTM在手机平台上使用提供了支撑——也就是添加了对PyTorch mobile的dynamic quantization的支持;增加了量化版本的sigmoid、leaky relu、batch_norm、BatchNorm2d、 Avgpool3d、quantized_hardtanh、quantized ELU activation、quantized Upsample3d、quantized batch_norm3d、 batch_norm3d + relu operators的fused、quantized hardsigmoid。
在PyTorch 1.6的时候,添加了quantized Conv1d、quantized hardswish、quantized layernorm、quantized groupnorm、quantized instancenorm、quantized reflection_pad1d、quantized adaptive avgpool、quantized channel shuffle op、Quantized Threshold;添加ConvBn3d, ConvBnReLU3d, BNReLU2d, BNReLU3d;per-channel的量化得到增强;添加对LSTMCell、RNNCell、GRUCell的Dynamic quantization支持; 在nn.DataParallel 和 nn.DistributedDataParallel中可以使用Quantization aware training;支持CUDA上的quantized tensor。
到目前的最新版本的PyTorch 1.7,又添加了Embedding 和EmbeddingBag quantization、aten::repeat、aten::apend、tensor的stack、tensor的fill_、per channel affine quantized tensor的clone、1D batch normalization、N-Dimensional constant padding、CELU operator、FP16 quantization的支持。
PyTorch对量化的支持目前有如下三种方式:
- Post Training Dynamic Quantization,模型训练完毕后的动态量化;
- Post Training Static Quantization,模型训练完毕后的静态量化;
- QAT(Quantization Aware Training),模型训练中开启量化。
在开始这三部分之前,Gemfield先介绍下最基础的Tensor的量化。
Tensor的量化
PyTorch为了实现量化,首先就得需要具备能够表示量化数据的Tensor,这就是从PyTorch 1.1之后引入的Quantized Tensor。 Quantized Tensor可以存储 int8/uint8/int32类型的数据,并携带有scale、zero_point这些参数。把一个标准的float Tensor转换为量化Tensor的步骤如下:
1 | >>> x = torch.rand(2,3, dtype=torch.float32) |
quantize_per_tensor函数就是使用给定的scale和zp来把一个float tensor转化为quantized tensor,后文你还会遇到这个函数。通过上面这几个数的变化,你可以感受到,量化tensor,也就是xq,和fp32 tensor的关系大概就是:
1 | xq = round(x / scale + zero_point) |
scale这个缩放因子和zero_point是两个参数,建立起了fp32 tensor到量化tensor的映射关系。scale体现了映射中的比例关系,而zero_point则是零基准,也就是fp32中的零在量化tensor中的值。因为当x为零的时候,上述xq就变成了:
1 | xq = round(zero_point) = zero_point |
现在xq已经是一个量化tensor了,我们可以把xq在反量化回来,如下所示:
1 | # xq is a quantized tensor with data represented as quint8 |
dequantize函数就是quantize_per_tensor的反义词,把一个量化tensor转换为float tensor。也就是:
1 | xdq = (xq - zero_point) * scale |
xdq和x的值已经出现了偏差的事实告诉了我们两个道理:
- 量化会有精度损失;
- 我们这里随便选取的scale和zp太烂,选择合适的scale和zp可以有效降低精度损失。不信你把scale和zp分别换成scale = 0.0036, zero_point = 0试试。
而在PyTorch中,选择合适的scale和zp的工作就由各种observer来完成。
Tensor的量化支持两种模式:per tensor 和 per channel。Per tensor 是说一个tensor里的所有value按照同一种方式去scale和offset; per channel是对于tensor的某一个维度(通常是channel的维度)上的值按照一种方式去scale和offset,也就是一个tensor里有多种不同的scale和offset的方式(组成一个vector),如此以来,在量化的时候相比per tensor的方式会引入更少的错误。PyTorch目前支持conv2d()、conv3d()、linear()的per channel量化。
Post Training Dynamic Quantization
这种量化方式经常缩略前面的两个单词从而称之为Dynamic Quantization,中文为动态量化。这是什么意思呢?你看到全称中的两个关键字了吗:Post、Dynamic:
Post:也就是训练完成后再量化模型的权重参数;
Dynamic:也就是网络在前向推理的时候动态的量化float32类型的输入。
Dynamic Quantization使用下面的API来完成模型的量化:1
torch.quantization.quantize_dynamic(model, qconfig_spec=None, dtype=torch.qint8, mapping=None, inplace=False)
quantize_dynamic这个API把一个float model转换为dynamic quantized model,也就是只有权重被量化的model,dtype参数可以取值 float16 或者 qint8。当对整个模型进行转换时,默认只对以下的op进行转换:
Linear
LSTM
LSTMCell
RNNCell
GRUCell
为啥呢?因为dynamic quantization只是把权重参数进行量化,而这些layer一般参数数量很大,在整个模型中参数量占比极高,因此边际效益高。对其它layer进行dynamic quantization几乎没有实际的意义。
再来说说这个API的第二个参数:qconfig_spec:qconfig_spec指定了一组qconfig,具体就是哪个op对应哪个qconfig ;
每个qconfig是QConfig类的实例,封装了两个observer;
这两个observer分别是activation的observer和weight的observer;
但是动态量化使用的是QConfig子类QConfigDynamic的实例,该实例实际上只封装了weight的observer;
activate就是post process,就是op forward之后的后处理,但在动态量化中不包含;
observer用来根据四元组(min_val,max_val,qmin, qmax)来计算2个量化的参数:scale和zero_point;
qmin、qmax是算法提前确定好的,min_val和max_val是从输入数据中观察到的,所以起名叫observer。
当qconfig_spec为None的时候就是默认行为,如果想要改变默认行为,则可以:
- qconfig_spec赋值为一个set,比如:{nn.LSTM, nn.Linear},意思是指定当前模型中的哪些layer要被dynamic quantization;
- qconfig_spec赋值为一个dict,key为submodule的name或type,value为QConfigDynamic实例(其包含了特定的Observer,比如MinMaxObserver、MovingAverageMinMaxObserver、PerChannelMinMaxObserver、MovingAveragePerChannelMinMaxObserver、HistogramObserver)。
事实上,当qconfig_spec为None的时候,quantize_dynamic API就会使用如下的默认值:
1 | qconfig_spec = { |
这就是Gemfield刚才提到的动态量化只量化Linear和RNN变种的真相。而default_dynamic_qconfig是QConfigDynamic的一个实例,使用如下的参数进行构造:
1 | default_dynamic_qconfig = QConfigDynamic(activation=default_dynamic_quant_observer, weight=default_weight_observer) |
其中,用于activation的PlaceholderObserver 就是个占位符,啥也不做;而用于weight的MinMaxObserver就是记录输入tensor中的最大值和最小值,用来计算scale和zp。
对于一个默认行为下的quantize_dynamic调用,你的模型会经历什么变化呢?Gemfield使用一个小网络来演示下:
1 | class CivilNet(nn.Module): |
原始网络和动态量化后的网络如下所示:
1 | #原始网络 |
可以看到,除了Linear,其它op都没有变动。而Linear被转换成了DynamicQuantizedLinear,DynamicQuantizedLinear就是torch.nn.quantized.dynamic.modules.linear.Linear类。没错,quantize_dynamic API的本质就是检索模型中op的type,如果某个op的type属于字典DEFAULT_DYNAMIC_QUANT_MODULE_MAPPINGS的key,那么,这个op将被替换为key对应的value:
1 | # Default map for swapping dynamic modules |
这里,nnqd.Linear就是DynamicQuantizedLinear就是torch.nn.quantized.dynamic.modules.linear.Linear。 但是,type从key换为value,那这个新的type如何实例化呢?更重要的是,实例化新的type一定是要用之前的权重参数的呀。没错,以Linear为例,该逻辑定义在 nnqd.Linear的from_float()方法中,通过如下方式实例化:
1 | new_mod = mapping[type(mod)].from_float(mod) |
from_float做的事情主要就是:
- 使用MinMaxObserver计算模型中op权重参数中tensor的最大值最小值(这个例子中只有Linear op),缩小量化时原始值的取值范围,提高量化的精度;
- 通过上述步骤中得到四元组中的min_val和max_val,再结合算法确定的qmin, qmax计算出scale和zp,参考前文“Tensor的量化”小节,计算得到量化后的weight,这个量化过程有torch.quantize_per_tensor和torch.quantize_per_channel两种,默认是前者(因为qchema默认是torch.per_tensor_affine);
- 实例化nnqd.Linear,然后使用qlinear.set_weight_bias将量化后的weight和原始的bias设置到新的layer上。其中最后一步还涉及到weight和bias的打包,在源代码中是这样的:
1 | #ifdef USE_FBGEMM |
也就是说依赖FBGEMM、QNNPACK这些backend。量化完后的模型在推理的时候有什么不一样的呢?在原始网络中,从输入到最终输出是这么计算的:
1 | #input |
而在动态量化模型中,上述过程就变成了:
1 | #input |
所以关键点就是这里的Linear op了,因为其它op和量化之前是一模一样的。你可以看到Linear权重的scale为0.0043458822183310986,zero_point为0。scale和zero_point怎么来的呢?由其使用的observer计算得到的,具体来说就是默认的MinMaxObserver,它是怎么工作的呢?还记得前面说过的observer负责根据四元组来计算scale和zp吧:
在各种observer中,计算权重的scale和zp离不开这四个变量:min_val,max_val,qmin, qmax,分别代表op权重数据/input tensor数据分布的最小值和最大值,以及量化后的取值范围的最小、最大值。qmin和qmax的值好确定,基本就是8个bit能表示的范围,这里取的分别是-128和127(更详细的计算方式将会在下文的“静态量化”章节中描述);Linear op的权重为torch.Tensor([[ 0.4097, -0.2896, -0.4931], [-0.3738, -0.5541, 0.3243]]),因此其min_val和max_val分别为-0.5541 和 0.4097,在这个上下文中,max_val将进一步取这俩绝对值的最大值。由此我们就可以得到:
- scale = max_val / (float(qmax - qmin) / 2) = 0.5541 / ((127 + 128) / 2) = 0.004345882…
- zp = 0
scale和zp的计算细节还会在下文的“静态量化”章节中更详细的描述。从上面我们可以得知,权重部分的量化是“静态”的,是提前就转换完毕的,而之所以叫做“动态”量化,就在于前向推理的时候动态的把input的float tensor转换为量化tensor。
在forward的时候,nnqd.Linear会调用torch.ops.quantized.linear_dynamic函数,输入正是上面(pack好后的)量化后的权重和float的bias,而torch.ops.quantized.linear_dynamic函数最终会被PyTorch分发到C++中的apply_dynamic_impl函数,在这里,或者使用FBGEMM的实现(x86-64设备),或者使用QNNPACK的实现(ARM设备上):
1 | #ifdef USE_FBGEMM |
等等,input还是float32的啊,这怎么运算嘛。别急,在上述的apply_dynamic_impl函数中,会使用下面的逻辑对输入进行量化:
1 | Tensor q_input = at::quantize_per_tensor(input_contig, q_params.scale, q_params.zero_point, c10::kQUInt8); |
也就是说,动态量化的本质就藏身于此:基于运行时对数据范围的观察,来动态确定对输入进行量化时的scale值。这就确保 input tensor的scale因子能够基于输入数据进行优化,从而获得颗粒度更细的信息。
而模型的参数则是提前就转换为了INT8的格式(在使用quantize_dynamic API的时候)。这样,当输入也被量化后,网络中的运算就使用向量化的INT8指令来完成。 而在当前layer输出的时候,我们还需要把结果再重新转换为float32——re-quantization的scale值是依据input、 weight和output scale来确定的,定义如下:
requant_scale = input_scale_fp32 * weight_scale_fp32 / output_scale_fp32
实际上,在apply_dynamic_impl函数中,requant_scales就是这么实现的:
1 | auto output_scale = 1.f |
这就是为什么在前面Gemfield提到过,经过量化版的fc的输出为torch.Tensor([[[[-1.3038, -0.3847], [1.2856, 0.3969]]]]),已经变回正常的float tensor了。所以动态量化模型的前向推理过程可以概括如下:
1 | #原始的模型,所有的tensor和计算都是浮点型 |
总结下来,我们可以这么说:Post Training Dynamic Quantization,简称为Dynamic Quantization,也就是动态量化,或者叫作Weight-only的量化,是提前把模型中某些op的参数量化为INT8,然后在运行的时候动态的把输入量化为INT8,然后在当前op输出的时候再把结果requantization回到float32类型。动态量化默认只适用于Linear以及RNN的变种。
Post Training Static Quantization
与其介绍post training static quantization是什么,我们不如先来说明下它和dynamic quantization的相同点和区别是什么。相同点就是,都是把网络的权重参数转从float32转换为int8;不同点是,需要把训练集或者和训练集分布类似的数据喂给模型(注意没有反向传播),然后通过每个op输入的分布特点来计算activation的量化参数(scale和zp)——称之为Calibrate(定标)。是的,静态量化包含有activation了,也就是post process,也就是op forward之后的后处理。为什么静态量化需要activation呢?因为静态量化的前向推理过程自(始+1)至(终-1)都是INT计算,activation需要确保一个op的输入符合下一个op的输入。
PyTorch会使用五部曲来完成模型的静态量化:
1,fuse_model
合并一些可以合并的layer。这一步的目的是为了提高速度和准确度:
1 | fuse_modules(model, modules_to_fuse, inplace=False, fuser_func=fuse_known_modules, fuse_custom_config_dict=None) |
比如给fuse_modules传递下面的参数就会合并网络中的conv1、bn1、relu1:
1 | torch.quantization.fuse_modules(gemfield_model, [['conv1', 'bn1', 'relu1']], inplace=True) |
一旦合并成功,那么原始网络中的conv1就会被替换为新的合并后的module(因为其是list中的第一个元素),而bn1、relu1(list中剩余的元素)会被替换为nn.Identity(),这个模块是个占位符,直接输出输入。举个例子,对于下面的一个小网络:
1 | class CivilNet(nn.Module): |
网络结构如下:
1 | CivilNet( |
经过torch.quantization.fuse_modules(c, [[‘fc’, ‘relu’]], inplace=True)后,网络变成了:
1 | CivilNet( |
modules_to_fuse参数的list可以包含多个item list,或者是submodule的op list也可以,比如:[ [‘conv1’, ‘bn1’, ‘relu1’], [‘submodule.conv’, ‘submodule.relu’]]。有的人会说了,我要fuse的module被Sequential封装起来了,如何传参?参考下面的代码:
1 | torch.quantization.fuse_modules(a_sequential_module, ['0', '1', '2'], inplace=True) |
不是什么类型的op都可以参与合并,也不是什么样的顺序都可以参与合并。就目前来说,截止到pytorch 1.7.1,只有如下的op和顺序才可以:
- Convolution, Batch normalization
- Convolution, Batch normalization, Relu
- Convolution, Relu
- Linear, Relu
- Batch normalization, Relu
实际上,这个mapping关系就定义在DEFAULT_OP_LIST_TO_FUSER_METHOD中:
1 | DEFAULT_OP_LIST_TO_FUSER_METHOD : Dict[Tuple, Union[nn.Sequential, Callable]] = { |
2,设置qconfig
qconfig是要设置到模型或者模型的子module上的。前文Gemfield就已经说过,qconfig是QConfig的一个实例,QConfig这个类就是维护了两个observer,一个是activation所使用的observer,一个是op权重所使用的observer。
1 | #如果要部署在x86 server上 |
如果是x86和arm之外呢?抱歉,目前不支持。实际上,这里的get_default_qconfig函数的实现如下所示:
1 | def get_default_qconfig(backend='fbgemm'): |
default_qconfig实际上是QConfig(activation=default_observer, weight=default_weight_observer),所以gemfield这里总结了一个表格:
| 量化的backend | activation | weight |
|---|---|---|
| fbgemm | HistogramObserver (reduce_range=True) | PerChannelMinMaxObserver (default_per_channel_weight_observer) |
| qnnpack | HistogramObserver (reduce_range=False) | MinMaxObserver (default_weight_observer) |
| 默认(非fbgemm和qnnpack) | MinMaxObserver (default_observer) | MinMaxObserver (default_weight_observer) |
3,prepare
prepare调用是通过如下API完成的:
1 | gemfield_model_prepared = torch.quantization.prepare(gemfield_model) |
prepare用来给每个子module插入Observer,用来收集和定标数据。以activation的observer为例,就是期望其观察输入数据得到四元组中的min_val和max_val,至少观察个几百个迭代的数据吧,然后由这四元组得到scale和zp这两个参数的值。
module上安插activation的observer是怎么实现的呢?还记得https://zhuanlan.zhihu.com/p/53927068一文中说过的“_forward_hooks是通过register_forward_hook来完成注册的。这些hooks是在forward完之后被调用的......”吗?没错,CivilNet模型中的Conv2d、Linear、ReLU、QuantStub这些module的_forward_hooks上都被插入了activation的HistogramObserver,当这些子module计算完毕后,结果会被立刻送到其_forward_hooks中的HistogramObserver进行观察。
这一步完成后,CivilNet网络就被改造成了:
1 | CivilNet( |
4,喂数据
这一步不是训练。是为了获取数据的分布特点,来更好的计算activation的scale和zp。至少要喂上几百个迭代的数据。
1 | #至少观察个几百迭代 |
5,转换模型
第四步完成后,各个op权重的四元组(min_val,max_val,qmin, qmax)中的min_val,max_val已经有了,各个op activation的四元组(min_val,max_val,qmin, qmax)中的min_val,max_val也已经观察出来了。那么在这一步我们将调用convert API:
1 | gemfield_model_prepared_int8 = torch.quantization.convert(gemfield_model_prepared) |
这个过程和dynamic量化类似,本质就是检索模型中op的type,如果某个op的type属于字典DEFAULT_STATIC_QUANT_MODULE_MAPPINGS的key(注意字典和动态量化的不一样了),那么,这个op将被替换为key对应的value:
1 | DEFAULT_STATIC_QUANT_MODULE_MAPPINGS = { |
替换的过程也和dynamic一样,使用from_float() API,这个API会使用前面的四元组信息计算出op权重和op activation的scale和zp,然后用于量化。动态量化”章节时Gemfield说过要再详细介绍下scale和zp的计算过程,好了,就在这里。这个计算过程覆盖了如下的几个问题:
- QuantStub的scale和zp是怎么来的(静态量化需要插入QuantStub,后文有说明)?
- conv activation的scale和zp是怎么来的?
- conv weight的scale和zp是怎么来的?
- fc activation的scale和zp是怎么来的?
- fc weight的scale和zp是怎么来的?
- relu activation的scale和zp是怎么来的?
- relu weight的…等等,relu没有weight。
我们就从conv来说起吧,还记得前面说过的Observer吗?分为activation和weight两种。以Gemfield这里使用的fbgemm后端为例,activation默认的observer是HistogramObserver、weight默认的observer是PerChannelMinMaxObserver。而计算scale和zp所需的四元组都是这些observer观察出来的呀(好吧,其中两个)。
在convert API调用中,pytorch会将Conv2d op替换为对应的QuantizedConv2d,在这个替换的过程中会计算QuantizedConv2d activation的scale和zp以及QuantizedConv2d weight的scale和zp。在各种observer中,计算scale和zp离不开这四个变量:min_val,max_val,qmin, qmax,分别代表输入的数据/权重的数据分布的最小值和最大值,以及量化后的取值范围的最小、最大值。qmin和qmax的值好确定,基本就是8个bit能表示的范围,在pytorch中,qmin和qmax是使用如下方式确定的:
1 | if self.dtype == torch.qint8: |
比如conv的activation的observer(quint8)是HistogramObserver,又是reduce_range的,因此其qmin,qmax = 0 ,127,而conv的weight(qint8)是PerChannelMinMaxObserver,不是reduce_range的,因此其qmin, qmax = -128, 127。那么min_val,max_val又是怎么确定的呢?对于HistogramObserver,其由输入数据 + 权重值根据L2Norm(An approximation for L2 error minimization)确定;对于PerChannelMinMaxObserver来说,其由输入数据的最小值和最大值确定,比如在上述的例子中,值就是-0.7898和-0.7898。既然现在conv weight的min_val,max_val,qmin, qmax 分别为 -0.7898、-0.7898、-128、 127,那如何得到scale和zp呢?PyTorch就是用下面的逻辑进行计算的:
1 | #qscheme 是 torch.per_tensor_symmetric 或者torch.per_channel_symmetric时 |
由此conv2d weight的谜团就被我们解开了:
scale = 0.7898 / ((127 + 128)/2 ) = 0.0062
zp = 0
再说说QuantStub的scale和zp是如何计算的。QuantStub使用的是HistogramObserver,根据输入从[-3,3]的分布,HistogramObserver计算得到min_val、max_val分别是-3、2.9971,而qmin和qmax又分别是0、127,其schema为per_tensor_affine,因此套用上面的per_tensor_affine逻辑可得:scale = (2.9971 + 3) / (127 - 0) = 0.0472
zp = 0 - round(-3 /0.0472) = 64
其它计算同理,不再赘述。有了scale和zp,就有了量化版本的module,上面那个CivilNet网络,经过静态量化后,网络的变化如下所示:
1 | #原始的CivilNet网络: |
静态量化模型如何推理?
我们知道,在PyTorch的网络中,前向推理逻辑都是实现在了每个op的forward函数中(参考:Gemfield:详解Pytorch中的网络构造)。而在convert完成后,所有的op被替换成了量化版本的op,那么量化版本的op的forward会有什么不一样的呢?还记得吗?动态量化中可是只量化了op的权重哦,输入的量化所需的scale的值是在推理过程中动态计算出来的。而静态量化中,统统都是提前就计算好的。我们来看一个典型的静态量化模型的推理过程:
1 | import torch |
网络forward的开始和结束还必须安插QuantStub和DeQuantStub,如上所示。否则运行时会报错:RuntimeError: Could not run ‘quantized::conv2d.new’ with arguments from the ‘CPU’ backend. ‘quantized::conv2d.new’ is only available for these backends: [QuantizedCPU]。
QuantStub在observer阶段会记录参数值,DeQuantStub在prepare阶段相当于Identity;而在convert API调用过程中,会分别被替换为nnq.Quantize和nnq.DeQuantize。在这个章节要介绍的推理过程中,QuantStub,也就是nnq.Quantize在做什么工作呢?如下所示:
1 | def forward(self, X): |
是不是呼应了前文中的“tensor的量化”章节?这里的scale和zero_point的计算方式前文也刚介绍过。而nnq.DeQuantize做了什么呢?很简单,把量化tensor反量化回来。
1 | def forward(self, Xq): |
是不是又呼应了前文中的“tensor的量化”章节?我们就以上面的CivilNet网络为例,当在静态量化后的模型进行前向推理和原始的模型的区别是什么呢?假设网络的输入为torch.Tensor([[[[-1,-2,-3],[1,2,3]]]]):
1 | c = CivilNet() |
假设conv的权重为torch.Tensor([[[[-0.7867]]]]),假设fc的权重为torch.Tensor([[ 0.4097, -0.2896, -0.4931], [-0.3738, -0.5541, 0.3243]]),那么在原始的CivilNet前向中,从输入到输出的过程依次为:
1 | #input |
而在静态量化的模型前向中,总体情况如下:
1 | #input |
Gemfield这里用原始的python语句来分步骤来介绍下。首先是QuantStub的工作:
1 | import torch |
我们特意在网络前面安插的QuantStub完成了自己的使命,其scale = 0.0472、zero_point = 64是静态量化完毕后就已经知道的,然后通过quantize_per_tensor调用把输入的float tensor转换为了量化tensor,然后送给接下来的Conv2d——量化版本的Conv2d:
1 | >>> c = nnq.Conv2d(1,1,1) |
同理,Conv2d的权重的scale=0.0062、zero_points=0是静态量化完毕就已知的,其activation的scale = 0.03714831545948982、zero_point = 64也是量化完毕已知的。然后送给nnq.Conv2d的forward函数(参考:https://zhuanlan.zhihu.com/p/53927068),其forward逻辑为:
1 | def forward(self, input): |
Conv2d计算完了,我们停下来反省一下。如果是按照浮点数计算,那么-0.7898 * -0.9912 大约是0.7828,但这里使用int8的计算方式得到的值是0.7801,这说明已经在引入误差了(大约为0.34%的误差)。这也是前面gemfield说的使用fuse_modules可以提高精度的原因,因为每一层都会引入类似的误差。
后面Linear的计算同理,其forward逻辑为:
1 | def forward(self, x): |
可以看到,所有以量化方式计算完的值现在需要经过activation的计算。这是静态量化和动态量化的本质区别之一:op和op之间不再需要转换回到float tensor了。通过上面的分析,我们可以把静态量化模型的前向推理过程概括为如下的形式:
1 | #原始的模型,所有的tensor和计算都是浮点型 |
最后再来描述下动态量化和静态量化的最大区别:
- 静态量化的float输入必经QuantStub变为int,此后到输出之前都是int;
- 动态量化的float输入是经动态计算的scale和zp量化为int,op输出时转换回float。
QAT(Quantization Aware Training)
前面两种量化方法都有一个post关键字,意思是模型训练完毕后所做的量化。而QAT则不一样,是指在训练过程中就开启了量化功能。
QAT需要五部曲,说到这里,你可能想到了静态量化,那不妨对比着来看。
1,设置qconfig
在设置qconfig之前,模型首先设置为训练模式,这很容易理解,因为QAT的着力点就是T嘛:
1 | cnet = CivilNet() |
使用get_default_qat_qconfig API来给要QAT的网络设置qconfig:
1 | cnet.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm') |
不过,这个qconfig和静态量化中的可不一样啊。前文说过qconfig维护了两个observer,activation的和权重的。QAT的qconfig中,activation和权重的observer都变成了FakeQuantize(和observer是has a的关系,也即包含一个observer),并且参数不一样(qmin、qmax、schema,dtype,qschema,reduce_range这些参数),如下所示:
1 | #activation的observer的参数 |
这里FakeQuantize包含的observer是MovingAverageMinMaxObserver,继承自前面提到过的MinMaxObserver,但是求最小值和最大值的方法有点区别,使用的是如下公式:
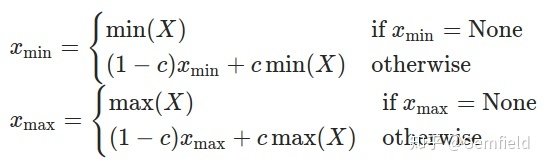
- Xmin、Xmax是当前运行中正在求解和最终求解的最小值、最大值;
- X是当前输入的tensor;
- c是一个常数,PyTorch中默认为0.01,也就是最新一次的极值由上一次贡献99%,当前的tensor贡献1%。
MovingAverageMinMaxObserver在求min、max的方式和其基类MinMaxObserver有所区别之外,scale和zero_points的计算则是一致的。那么在包含了上述的observer之后,FakeQuantize的作用又是什么呢?看下面的步骤。
2,fuse_modules
和静态量化一样,不再赘述。
3,prepare_qat
在静态量化中,我们这一步使用的是prepare API,而在QAT这里使用的是prepare_qat API。最重要的区别有两点:
- prepare_qat要把qconfig安插到每个op上,qconfig的内容本身就不同,参考五部曲中的第一步;
- prepare_qat 中需要多做一步转换子module的工作,需要inplace的把模型中的一些子module替换了,替换的逻辑就是从DEFAULT_QAT_MODULE_MAPPINGS的key替换为value,这个字典的定义如下:因此,同静态量化的prepare相比,prepare_qat在多插入fake_quants、又替换了nn.Conv2d、nn.Linear之后,CivilNet网络就被改成了如下的样子:
1
2
3
4
5
6
7
8
9
10
11
12# Default map for swapping float module to qat modules
DEFAULT_QAT_MODULE_MAPPINGS : Dict[Callable, Any] = {
nn.Conv2d: nnqat.Conv2d,
nn.Linear: nnqat.Linear,
# Intrinsic modules:
nni.ConvBn1d: nniqat.ConvBn1d,
nni.ConvBn2d: nniqat.ConvBn2d,
nni.ConvBnReLU1d: nniqat.ConvBnReLU1d,
nni.ConvBnReLU2d: nniqat.ConvBnReLU2d,
nni.ConvReLU2d: nniqat.ConvReLU2d,
nni.LinearReLU: nniqat.LinearReLU
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37CivilNet(
(conv): QATConv2d(
1, 1, kernel_size=(1, 1), stride=(1, 1), bias=False
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
)
(fc): QATLinear(
in_features=3, out_features=2, bias=False
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
)
(relu): ReLU(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
)
(quant): QuantStub(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), scale=tensor([1.]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([]), max_val=tensor([]))
)
)
(dequant): DeQuantStub()
)
4,喂数据
和静态量化完全不同,在QAT中这一步是用来训练的。我们知道,在PyTorch的网络中,前向推理逻辑都是实现在了每个op的forward函数中(参考:Gemfield:详解Pytorch中的网络构造)。而在prepare_qat中,所有的op被替换成了QAT版本的op,那么这些op的forward函数有什么特别的地方呢?
Conv2d被替换为了QATConv2d:
1 | def forward(self, input): |
Linear被替换为了QATLinear:
1 | def forward(self, input): |
ReLU还是那个ReLU,不说了。总之,你可以看出来,每个op的输入都需要经过self.weight_fake_quant来处理下,输出又都需要经过self.activation_post_process来处理下,这两个都是FakeQuantize的实例,只是里面包含的observer不一样。以Conv2d为例:
1 | #conv2d |
而FakeQuantize的forward函数如下所示:
1 | def forward(self, X): |
FakeQuantize中的fake_quantize_per_channel_or_tensor_affine实现了quantize和dequantize,用公式表示的话为:out = (clamp(round(x/scale + zero_point), quant_min, quant_max)-zero_point)*scale。也就是说,这是把量化的误差引入到了训练loss之中呀!
这样,在QAT中,所有的weights和activations就像上面那样被fake quantized了,且参与模型训练中的前向和反向计算。float值被round成了(用来模拟的)int8值,但是所有的计算仍然是通过float来完成的。 这样以来,所有的权重在优化过程中都能感知到量化带来的影响,称之为量化感知训练(支持cpu和cuda),精度也因此更高。
5,转换
这一步和静态量化一样,不再赘述。需要注意的是,QAT中,有一些module在prepare中已经转换成新的module了,所以静态量化中所使用的字典包含有如下的条目:
1 | DEFAULT_STATIC_QUANT_MODULE_MAPPINGS = { |
总结下来就是:
1 | # 原始的模型,所有的tensor和计算都是浮点 |
总结
那么如何更方便的在你的代码中使用PyTorch的量化功能呢?一个比较优雅的方式就是使用deepvac规范——这是一个定义了PyTorch工程标准的项目:https://github.com/DeepVAC/deepvac
原文链接: PyTorch

