最近需要验证一个bit_cast转换函数在GPU kernel里面的底层实现形式,之前一直猜想是Mov指令完成的,CPU端的代码往往通过gdb反汇编很容易看到每行代码对应个汇编语言,但是对于GPU的kernel,我却一直没有什么经验。刚好可以利用Intel最近准备release的OneAPI 开发工具包,借助里面的gdb-oneapi和VTune工具来实现。本文就是记录这次踩坑过程。
Locate performance bottlenecks fast. Advanced sampling and profiling techniques quickly analyze your code, isolate issues, and deliver insights for optimizing performance on modern processors.
Source Code 先上测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #pragma OPENCL EXTENSION cl_khr_fp16 : enable #include <iostream> #include <CL/sycl.hpp> //class kernel1; class kernel2; namespace sycl = cl::sycl; template <typename To, typename From> To bit_cast(const From &from) { #if __cpp_lib_bit_cast return std::bit_cast<To>(from); #else #if __has_builtin(__builtin_bit_cast) return __builtin_bit_cast(To, from); // clang path #else To to; detail::memcpy(&to, &from, sizeof(To)); return to; #endif // __has_builtin(__builtin_bit_cast) #endif // __cpp_lib_bit_cast } void add() { sycl::float4 a = {1.0, 2.0, 3.0, 4.0}; sycl::float4 b = {4.0, 3.0, 2.0, 3.0}; sycl::float4 c = {.0, 0.0, 0.0, 0.0}; sycl::default_selector device_selector; sycl::queue queue(device_selector); std::cout << "Running on " << queue.get_device().get_info<sycl::info::device::name>() << "\n"; { sycl::buffer<sycl::float4, 1> a_sycl(&a, sycl::range<1>(1)); sycl::buffer<sycl::float4, 1> b_sycl(&b, sycl::range<1>(1)); sycl::buffer<sycl::float4, 1> c_sycl(&c, sycl::range<1>(1)); queue.submit([&] (sycl::handler& cgh) { auto a_acc = a_sycl.get_access<sycl::access::mode::read>(cgh); auto b_acc = b_sycl.get_access<sycl::access::mode::read>(cgh); auto c_acc = c_sycl.get_access<sycl::access::mode::discard_write>(cgh); cgh.single_task<class vector_addition>([=] () { c_acc[0] = a_acc[0] + b_acc[0]; }); }); } std::cout << " A { " << a.x() << ", " << a.y() << ", " << a.z() << ", " << a.w() << " }\n" << "+ B { " << b.x() << ", " << b.y() << ", " << b.z() << ", " << b.w() << " }\n" << "------------------\n" << "= C { " << c.x() << ", " << c.y() << ", " << c.z() << ", " << c.w() << " }" << std::endl; } void bitCast() { // sycl::gpu_selector device_selector; // sycl::queue queue(device_selector); cl::sycl::queue queue; std::cout << "Running on " << queue.get_device().get_info<cl::sycl::info::device::name>() << "\n"; constexpr size_t LENGTH = 64; unsigned short res[64] = {0}; cl::sycl::range<1> data_range {LENGTH}; { cl::sycl::buffer<unsigned short, 1> buf_res(res, 1); cl::sycl::half tmp(0.0f); queue.submit([&] (sycl::handler& cgh) { auto a_acc = buf_res.get_access<sycl::access::mode::discard_write>(cgh); cgh.parallel_for<class kernel2>(data_range, [=](cl::sycl::id<1> index) { a_acc[index] = bit_cast<unsigned short, cl::sycl::half>(tmp); // a_acc[index] = 0x42; //a_acc[0] = __builtin_bit_cast(unsigned short, tmp); }); }); queue.wait_and_throw(); } std::cout << "bit_cast " << res[0] << std::endl; } int main() { add(); bitCast(); return 0; }
这段code比较简单,借助SYCL环境,有两个functions,add()``用来验证简单的scalar 加法,bitCast()用来验证`__builtin_bit_cast() function(需要clang++编译器支持)。a_acc[index] = bit_cast<unsigned short, cl::sycl::half>(tmp);对应的汇编代码实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cl::sycl::range<1> data_range {LENGTH}; { cl::sycl::buffer<unsigned short, 1> buf_res(res, 1); cl::sycl::half tmp(0.0f); queue.submit([&] (sycl::handler& cgh) { auto a_acc = buf_res.get_access<sycl::access::mode::discard_write>(cgh); cgh.parallel_for<class kernel2>(data_range, [=](cl::sycl::id<1> index) { a_acc[index] = bit_cast<unsigned short, cl::sycl::half>(tmp); // a_acc[index] = 0x42; //a_acc[0] = __builtin_bit_cast(unsigned short, tmp); }); }); queue.wait_and_throw(); }
Build build步采用makefile来编译。
1 source /home/zhiyuanh/intel/inteloneapi/setvars.sh
makefile文件夹内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ONE_API_ROOT := /home/zhiyuanh/intel/inteloneapi SYCL_ROOT := ${ONE_API_ROOT}/compiler/latest/linux SYCLCXX := $(SYCL_ROOT)/bin/clang++ CXXFLAGS := -I $(SYCL_ROOT)/lib/clang/10.0.0/include -fsycl -g -O0 LDFLAGS := -L $(SYCL_ROOT)/lib -lOpenCL -fsycl -g first.o: first.cpp $(SYCLCXX) -std=c++11 $(CXXFLAGS) -c first.cpp clean: rm -f first.exe first.o
之后make生成first目标文件。
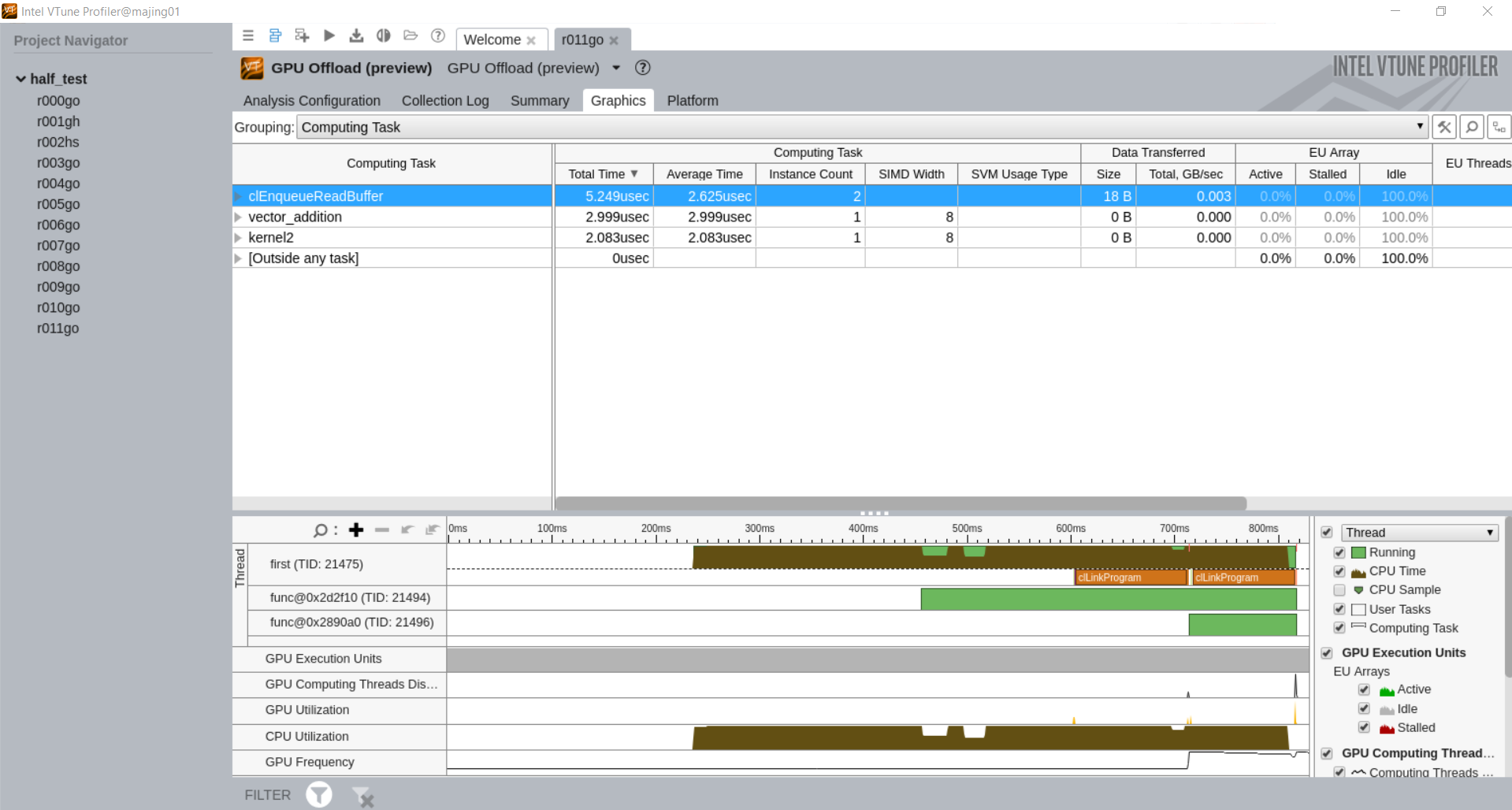
Vtune采集 导入vtune并选择GPU offload(preview)模式。
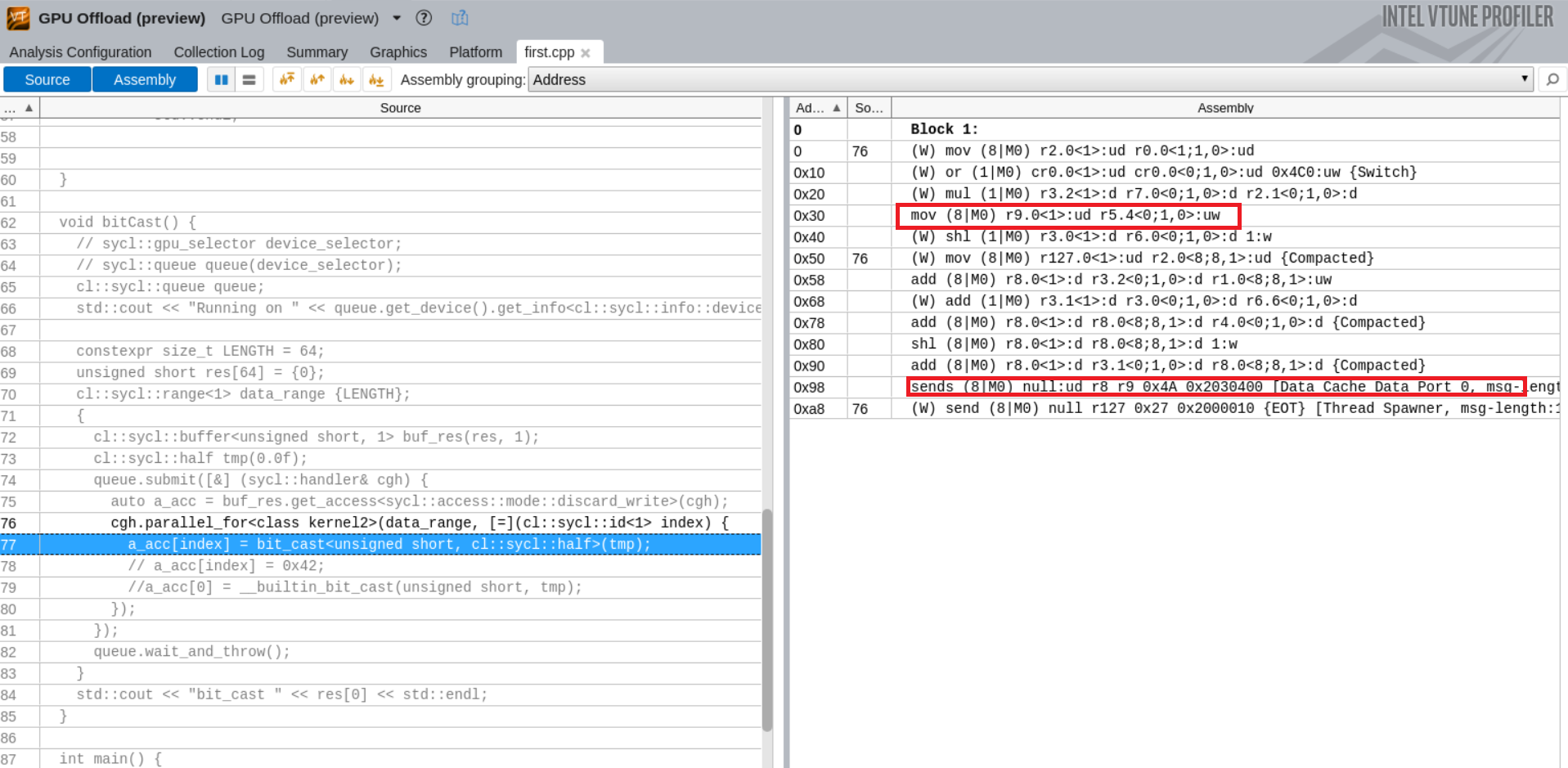
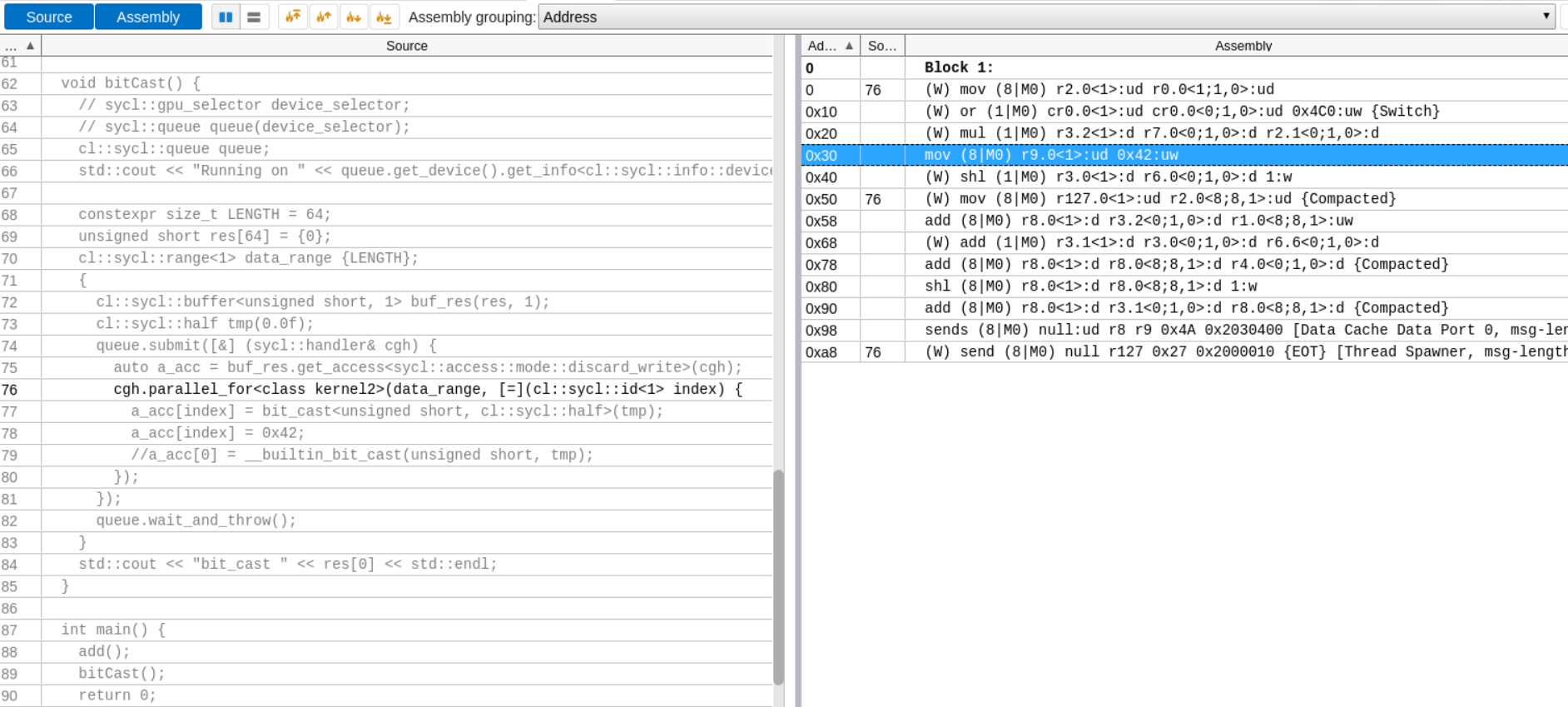
查看对应的source code和生成的汇编code。
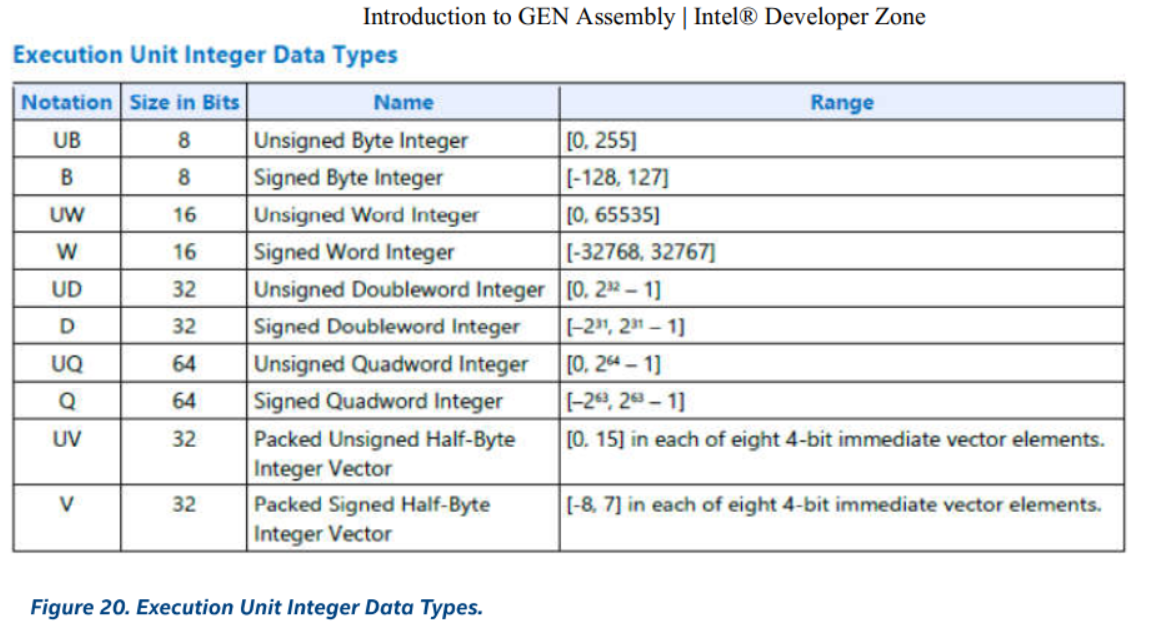
这里猜想77行内的源代码对应的是右边标红的mov指令,因为cl::sycl::half共有16个bit,对应的汇编符号是UW。该mov指令将一个UW写到r9寄存器,然后再最后send发射出去。中间没有任何一个环节有修改r9的指令。
这里做一小测试,将77行注释,换成一行a_acc[index] = 0x42常量赋值,如果真是对应那条mov指令,那么现在的新的指令里面会有0x42这个立即数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cl::sycl::range<1> data_range {LENGTH}; { cl::sycl::buffer<unsigned short, 1> buf_res(res, 1); cl::sycl::half tmp(0.0f); queue.submit([&] (sycl::handler& cgh) { auto a_acc = buf_res.get_access<sycl::access::mode::discard_write>(cgh); cgh.parallel_for<class kernel2>(data_range, [=](cl::sycl::id<1> index) { //a_acc[index] = bit_cast<unsigned short, cl::sycl::half>(tmp); a_acc[index] = 0x42; //a_acc[0] = __builtin_bit_cast(unsigned short, tmp); }); }); queue.wait_and_throw(); }
结论 bit_cast转换函数在GPU kernel里面的底层实现形式,之前一直猜想是Mov指令完成的,但也有一些其他额外的指令比如mul, or, shl这些可能是算地址偏移量相关。