
在不同DL硬件上部署各种深度学习模型,促进了社区深度学习编译器的研发。从行业和学术界已经提出了几个DL编译器,如Tensorflow XLA和TVM。同样,DL编译器将不同DL框架中描述的DL模型作为输入,然后为不同的DL硬件生成优化的代码作为输出。然而,现有的调查没有全面分析DL-编译器的独特设计。在本文中,我们对现有DL编译器进行了全面调查,对常见设计进行了详细剖析,重点介绍了面向DL的多级IR和前端后端优化。从不同方面,我们对现有DL和编译器进行了全面的比较。此外,我们还详细介绍了多级IR设计和编译器优化技术。最后几个见解被突出显示为DL编译器的潜在研究方向。这是一份重点介绍DL编译器独特设计的最值得关注的调查论文,我们希望,这能为未来DL编译器的研究铺平道路。
Introduction
深度学习的发展对各种科学型产品产生了深远的影响。 它不仅在自然语言处理(NLP)和计算机视觉(CV)等艺术智能(NLP)和计算机视觉(CV)方面表现出非凡的价值,而且在电子商务、智能城市和药物发现等更广泛的应用方面也取得了巨大成功。随着卷积神经网络(CNN)、循环神经网络(RNN)、长期短期内存(LSTM)和生成对抗性网络等多功能深度学习模型的出现,简化各种DL模型的编程以实现其广泛采用至关重要。
在业界和学术界的不断努力下,提出了几种流行的DL编程框架,如TensorFlow、PyTorch、MXNet和CNTK,以简化各种DL模型的应用。尽管上述DL编程框架中存在优势和弱点,具体取决于其设计中的权衡,但当互操作性支持现有DL模型中新出现的DL模型时,模型在不同的FWK直接转化对于减少冗余工程工作变得非常重要。为了改进转换的简便性,ONNX已提出定义用于表示DL模型的开源格式。(Open Neural Network Exchange)
同时,矩阵乘法GEMM等独特的计算特性激发了芯片架构师设计定制DL芯片更高效率的热情。互联网巨头(例如谷歌TPU,Hisilicon NPU, Apple Bonic),处理器供应商(例如,NVIDIA 图灵,英特尔 NNP),服务提供商(例如,亚马逊,阿里巴巴寒光),甚至初创公司(例如,Cambricon,Graphcore)正在投入庞大的劳人力物力研发。一般来说,DL芯片的类别包括:
- 通用芯片与软件硬件共同设计;
- 专为DL机型定制的专用芯片;
- 受生物脑和科学启发的神经形态芯片。
通用芯片(例如 CPU、GPU)添加了特殊的硬件和组件,如AVX512矢量单元和Tensor core以加速DL模型。而对于专用芯片(如 Google Tensor处理单元(TPU),应用规格集成电路(例如矩阵乘法引擎和高带宽内存)的设计旨在将性能和能量耗竭提升到极致。在可预见的将来,DL芯片的设计将更加多样化。
为了加速不同DL芯片上的DL模型,将计算映射到DL芯片非常重要。在通用芯片上,高度优化的线性代数库(如基本线性代数子程序 (BLAS) 库(例如 MKL 和 cuBLAS)是 DL 模型的”精效计算”的基础。以卷积convolution为例,DL 框架将卷积转换为矩阵乘法,然后在 BLAS+ 库中调用 GEMM 函数。此外,芯片供应商还发布了专为DL计算(例如 MKL-DNN 和 cuDNN)量身定制的优化加速库,包括forward和backward convolution、pooling、normlization和activation。还开发了更先进的工具,以进一步加快DL操作。以TensorRT为例,它支持图优化(例如层融合)和低位量化(int8/half),并大量收集高度优化的GPU内核。在专用DL芯片上,供应商还提供类似的库以及工具链,以便有效地执行DL+模型。但是依靠上述库和工具在不同DL芯片上映射DL模型的缺点是,它们通常落后于DL模型的快速发展,因此未能有效地利用DL芯片。
为了解决DL库和工具的缺点,以及减轻手动优化每个DL芯片上的DL模型的负担,DL社区采用了域规范 + 编译器技术进行弥补徐。很快已经提出了几个流行的DL编译器,如[TVM,Tensor Comprehensive,Glow,nGraph和XLA,都是来自工业和学术界。DL编译器将DL框架中描述的模型定义的描述视为输入,并在各种DL芯片上生成最成熟的代码实现作为输出。模型定义和规范代码实现之间的转换是高度优化的目标 - 模型规范和硬件体系结构。例如,DL编译器集成了面向DL的优化,如层和运算符融合,可实现高度code gen。此外现有的DL编译器还利用了通用编译器(例如LLVM)的成熟工具链,它在不同的硬件体系结构中提供了更好的可移植性。但是DL编译器的独特性在于多层IR和DL特定优化的设计。
本文我们提供一个对现有的DL编译器的综合调查,具体包括前端、多层IR和后端,并特别强调IR的设计和优化方法。据我们所知,这是一篇对DL编译器设计进行全面调查的论文。本文的贡献如下:
- 我们从硬件支持、DL框架支持、代码生成和优化等各个方面对现有DL编译器进行了全面比较,这些代码生成和优化可用作为最终用户选择合适DL编译器的指南。
- 我们剖析了现有DL编译器的一般设计,并详细分析了多级IR设计和编译器优化技术,如数据流优化、硬件指令映射、内存延迟隐藏和数据并行化技术。
- 我们为DL编译器的未来发展提供了一些见解,包括auto-tuning、多面体编译器、量化、差异化编程和隐私保护,我们希望推动DL编译器社区的研究。
本文的剩余部分按如下方式组织。第 2 节介绍了 DL 编译器的背景,包括 DL 框架、DL 芯片以及特定于硬件(FPGA)的DL编译器。第 3 节提供了现有 DL 编译器之间的详细比较。第 4 节介绍了 DL 编译器的一般设计,重点介绍IR和前后端优化。第 5 节总结了本文,并重点介绍了未来的方向。
Background
Deep Learning Frameworks
在这部分,我们将概述流行的深度学习框架。讨论可能并非详尽无遗,但旨在为DL从业人员提供一个准则。下图介绍了DL框架的总况,包括当前流行的框架、历史框架和 ONNX 支持的框架。
TensorFlow
TensorFlow在2015年被Google首次发布,在所有的深度学习框架里面,TF有最为广泛支持的语言接口,包括C++, Python, Java, GO, R和Haskell。TensorFlow™是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。TensorFlow Lite是为移动端和嵌入式设备设计的神经网络API而设计。为了降低使用的复杂程度使用户更加容易上手,Google把Keras作为TF的前端内核。除此之外和PyTorch支持动态计算题相比,TF eager-model提供了类似的功能。
Keras
Keras于2015年3月首次发布,由Google支持。Keras 是一个高级网络库,用于快速构建 DL 模型,该模型是纯 Python 编写的。虽然Keras本身不是DL框架,但它提供了一个与TensorFlow、MXNet、Theano 和 CNTK 集成的高级别 API。借助 Keras,DL 开发人员只需几行代码就构建神经网络。此外,Keras 可以集成其他常见的 DL 包,例如Python的scikit学习。但是由于过度封装,Keras 不够灵活,因此很难添加operator算子或获取Low-level数据信息。
PyTorch
PyTorch于2017年初由Facebook推出。Facebook 在Python中重写了基于Lua DL框架Torch,并在Tensor级别上重构了所有模块。此外最流行的动态框架,PyTorch嵌入了用于在Python中构造动态数据流图的基元,其中控制流在Python解释器中执行。PyTorch1.0集成了PyTorch 0.4 和 Caffe2的代码库,以创建一个统一的框架。这使得 PyTorch 能够吸收 Caffe2 的好处,以支持高效的图形执行和移动部署。FastAI是基于 PyTorch 的上层封装的高级 API 层。它完全借用 Keras 来提高 Pytorch 的易用性。
Caffe/Caffe2
Caffe专为2014年加州大学伯克利分校的深度学习和分类而设计。Caffe 支持命令行、Python和MATLAB API。Caffe的一个重要功能是无需编写代码即可训练和部署模型。Caffe 的简单框架使其代码易于扩展,适合开发人员进行深入分析。因此,Caffe主要定位在研究上,从起源于至今,它流行起来。Caffe2基于原始的 Caffe 项目,支持移动(例如iOS和Android)和服务器(例如 Linux、Windows 和 Mac)构建平台。Caffe2 在结构上与 TensorFlow 类似,尽管具有较轻的 API,并且使访问计算图中的中间结果更加容易。
MXNet
Apache MXNet支持多种语言 AP,包括 Python、C++、R、Scala、Julia、Matlab 和 JavaScript。该项目于 2015 年 9 月开始,版本 1.0.0 于 2017 年 12 月发布。MXNet 旨在可扩展,从系统角度设计,以减少数据加载和 I/O 复杂性。MXNet提供了不同的范例:像 Caffe 和 Tensorflow 这样的命令性编程,以及像 PyTorch 这样的命令性编程。2017 年 12 月,亚马逊和微软联合发布了Gluon,这是一个类似于基于 MXNet 的 Keras 和 FastAI 的高级界面。Gluon 的最大特点是它既支持灵活的动态图形,又支持高效的静态图形。Gluon现在可用在Apache MXNet 和微软认知工具包CNTK。
CNTK
微软认知工具包(也称为 CNTK)于 2015 年 10 月开发。CNTK 可以通过 Python、C++ 和 C# API 或它自己的脚本语言(即 BrainScript)使用。CNTK 设计为易于使用和生产就绪,可用于大型生产规模数据,在 Linux 和 Windows 上受支持。但是,CNTK 尚不支持 ARM 体系结构,它限制了其在移动设备上的使用。CNTK 使用类似于 TensorFlow 和 Caffe 的静态计算图,其中神经网络被视为通过定向图形的一系列计算步骤。
PaddlePaddle
2016 年 8 月,百度开源的 PadlePadle,一个 DL 在内部使用多年。PadlePadle可应用于自然语言处理、图像识别、推荐引擎等。PadlePadle 的原始设计类似于 Caffe,其中每个模型都可以表示为一组图层。2017年4月,百度推出了Padpadle v2,它增加了运营商的概念,参照TensorFlow,将层分解为粒度更细的运营商,从而支持更复杂的网络结构。此外,PadlePadle 于 2017 年后期推出。流体与PyTorch类似,因为它提供自己的解释器,以便不受Python性能限制。
ONNX
开放神经网络交换(ONNX)由微软和2017 年 9 月发布。ONNX 定义了一个可扩展的计算图形模型,由不同的 DL 框架构建的计算图可以转换为该模型。ONNX 使在 DL 框架之间转换模型更加容易。例如,它允许开发人员构建 MXNet 模型,然后使用 PyTorch 运行模型进行推理。如图所示,ONNX 已集成到 PyTorch、MXNet、PadlePadle 等中。对于尚未直接支持的几个 DL 框架(例如,TensorFlow 和 Keras),ONNX 会向它们添加转换器。
Historical Frameworks
由于DL社区的迅速发展,许多历史DL框架不再存在或活跃。例如,Facebook提议的PyTorch已经取代了Torch。作为最古老的 DL 框架之一,Theano不再受维护。Deeplearning4J基于Java和Scala的分布式DL框架,但是由于缺乏大型开发人员社区(如PyTorch),它变得不活跃。Chainer曾经是动态计算图形的首选框架,但被具有类似功能的 MXNet、PyTorch 和 TensorFlow 所取代。
先前的工作比较了 DL 框架在不同应用程序(例如计算机视觉和图像分类)和不同硬件目标(例如 CPU、GPU 和 TPU)上的性能。有关每个 DL 框架的详细调查。本调查侧重于 DL 编译器的研究工作,这些编译器提供了更通用的方法,可在各种硬件上高效执行各种 DL 模型。

Deep Learning Hardwares
DL硬件可以根据通用性分为三类:(注,原文里面是four categories,应该是笔误 )
- 通用硬件(Neuromorphic Hardware),可以通过硬件和软件优化支持DL工作负载;
- 专用硬件(Dedicated Hardware),专注于通过完全定制的电路设计加速 DL 工作负载;
- 通过模仿人脑功能的神经形态硬件(Neuromorphic Hardware)
Neuromorphic Hardware
DL模型最具代表性的通用硬件是图形处理单元 (GPU),它实现了与多核架构的高并行性。Tensor core可以同时加速混合精度矩阵乘积计算,在训练和推理过程中,DL 模型中广泛使用。NVIDIA 还与硬件一起优化,还推出了高度优化的 DL 库和工具,如 cuDNN和 TensorRT,以进一步加快 DL 模型的计算。
Dedicated Hardware
专用硬件完全定制用于 DL 计算,可将性能和能效提高至极致。DL 应用程序和算法的快速扩展促使许多初创公司开发专用 DL 硬件(例如,Graphcore GC2、Cambricon MLU270)。此外,传统硬件公司(如英特尔NNP、高通云AI 100)和云服务提供商(如谷歌TPU、亚马逊和阿里巴巴汉光)也在此领域投资。最有名的专用DL硬件是谷歌的TPU系列。TPU 包括矩阵乘法单元 (MXU)、统一缓冲区 (UB) 和激活单元 (AU),由主机处理器使用 CISC 指令驱动。MXU 主要由收缩数组组成,该阵列针对执行矩阵乘法时功率和面积效率进行了优化。与 CPU 和 GPU 相比,TPU 仍然是可编程的,但使用矩阵作为基元而不是矢量或标量。亚马逊推断最近也引起了关注。该芯片有四个神经核心,专为张量级操作而设计,并且具有较大的片上缓存,以避免频繁的主内存访问。
Neuromorphic Hardware
神经形态芯片使用电子技术来模拟生物大脑。这种具有代表性的产品是IBM的ThiNorth和英特尔的Loihi。神经形态芯片(例如,TrueNorth)在人工神经元之间具有非常高的连接性。神经形态芯片还可以复制类似于脑组织的结构:神经元可以同时存储和处理数据。传统芯片在不同的位置分配处理器和内存,但神经形态芯片通常有许多微处理器,每个微处理器都有少量的本地内存。与 TrueNorth 相比,Loihi 的学习能力与大脑更相似。Loihi 引入了脉冲时间依赖突触可塑性模型 (STDP),这是一种机制,通过突触前脉冲和突触后脉冲的相对时间来调节突触强度。然而,神经形态芯片离大规模商业生产还很远。尽管如此,在计算机科学领域,神经形态芯片可以帮助捕捉快速,终身学习的过程,这是忽略定期DL模型,并在神经学领域,他们有助于找出大脑的各个部分如何协同工作,创造思想,感觉,甚至意识。
硬件特定的 DL 编译器
FPGA是可重新编程的集成电路,包含一系列可编程逻辑块。开发人员可以在制造后配置它们。除了可重新编程的性质外,FPGA的低功率和高性能性质使其广泛应用于通信、医疗、图像处理和 ASIC 原型设计等众多领域。至于深度学习领域,高性能 CPU 和 GPU 可高度可重新编程,但功耗高,而高能效的 ASIC 专用于固定应用。然而,FPGA可以弥补CPU/GPU和SIC之间的差距,这使得FPGA成为一个有吸引力的深度学习平台。
High-Level Synthesis(HLS) 编程模型使 FPGA 程序员能够使用高级语言(如 C 和高级语言)方便地生成有效的硬件C++。它避免编写大量 Verilog 或 VHDL 描述,从而降低了编程阈值并减少了长设计圈。Xilinx Vivado HLS 和英特尔 OpenCL 的 FPGA SDK 是两种针对他们自己的 FPGA 的流行的 HLS 工具。但是,即使使用 HLS,将 DL 模型映射到 FPGA 仍是一项复杂的工作,因为 1) DL 模型通常由 DL 框架的语言而不是裸露的心理 C/C++ 代码描述,并且 2) DL 特定信息和优化很难被利用。
针对 FPGA 的特定于硬件的 DL 编译器以 DL 模型或其特定于域的语言 (DSL) 作为输入,进行特定于域(关于 FPGA 和 DL)的优化和映射,然后生成 HLS 或 Verilog/DLVH,最后生成比特流。根据基于 FPGA 的加速器生成的体系结构,它们可以分为两类:处理器体系结构和流式处理体系结构。
处理器体系结构(The processor architecture)与通用处理器具有相似性。此体系结构的 FPGA 加速器通常由多个处理单元 (PUs) 组成,这些单元由片上缓冲器和多个较小的处理引擎 (PEs) 组成。它通常具有虚拟指令集 (ISA),硬件的控制和执行的调度应该由软件确定。更重要的是,静态调度方法避免了冯·诺伊曼执行的开销(包括指令提取和解码)。硬件模板是具有可的通用和通用实现。针对此体系结构的 DL 编译器采用硬件模板自动生成加速器设计。借助模板的可配置参数,编译器实现了可扩展性和灵活性。可伸缩性意味着编译器可以生成从高性能到高能效的 FPGA 设计,灵活性意味着编译器可以生成具有不同层类型和参数的各种 DL 模型的设计。每个 PU 的 PU 数和 PEs 的数量是重要的模板参数。此外,tile size和batch size也是将DL模型映射到P、PEs的基本调度参数。所有这些参数通常由设计空间探索使用各种策略确定,例如组合性能模型和自动调整。DNN Weaver, Angel-Eye,阿拉莫, FP-DNN, SysArrayAccel是典型的 FPGA DL 编译器,针对处理器体系结构。此外,PUs 和 PEs 通常负责粗粒度基本操作,如矩阵矢量乘法、矩阵矩阵乘法、池化和某些元素操作。这些基本操作的优化主要以并行和数据重用之间的权衡为指导,这与一般优化类似。
流式处理体系结构(The streaming architecture)与管道(pipelines)有相似之处。此体系结构的 FPGA 加速器由多个不同的硬件块组成,并且它几乎为输入 DL 模型的每一层有一个硬件块。使用 DL 模型的输入数据,此类加速器会以与图层相同的顺序通过不同的硬件块处理数据。此外,使用流式处理输入数据,所有硬件块都可以以管道方式充分利用。但是,流式处理体系结构通常遵循一个初始假设,即目标 FPGA 上的芯片内存计算资源足以适应 DL 模型,这带来了部署具有复杂层的深度模型的障碍。针对此体系结构的 DL 编译器可以通过利用 FPGA 的可重构性或采用动态控制流来解决此问题。单个块的进一步优化类似于处理器体系结构的基本操作。fpgaConvNet, DeepBurning,Haddoc2 和AutoCodeGen是典型的对应的 DL 编译器。
COMPARISON OF DL COMPILERS
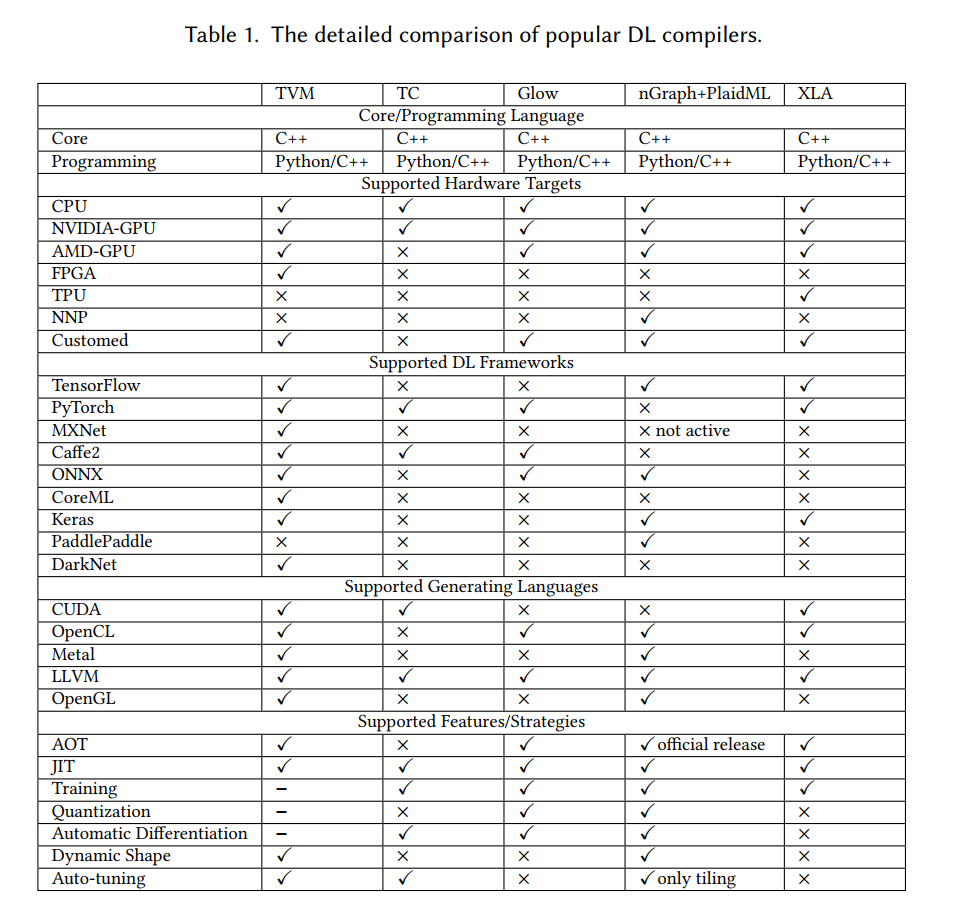
在本节中,我们比较了几个流行的DL编译器,包括TVM、TC、Glow、nGraph、PlaidML和XLA。上表显示了不同 DL 编译器从各个方面的详细比较,其中”+”表示受支持,”+”表示不支持,”+”表示正在开发中。请注意,我们使用 TVM 来表示VTA、中继和autoTVM的工作。此外,PlaidML 与 nGraph 紧密耦合,因此我们在比较过程中将它们一起考虑。此外,对于DL编译器的性能比较。
核心/编程语言 所有 DL 编译器的核心语言C++,C++在设计中强调性能、效率和使用灵活性。然而,Python 由于其简单性和可用性,越来越受程序员的欢迎。对于大多数成熟的DL编译器(例如,TVM、TC、nGraph、PlaidML 和 XLA),其 Python 接口几乎涵盖了所有核心功能。
支持的硬件 所有 DL 编译器都支持英特尔和 AMD CPU 以及 NVIDIA GPU。TC 的官方版本目前不为 AMD GPU 提供支持。请注意,nGraph 与 PlaidML 集成,以加速更多硬件目标。nGraph 可以通过调用现有的内核库(例如 cuDNN 和 MKL-DNN)来支持目标硬件。此外,PlaidML 还提供广泛的硬件目标支持,因为它能够生成代码。TVM 可以使用 VTA 体系结构和运行时将工作负载映射到FPGA。DL 编译器的本机支持的专用 DL 芯片通常与开发人员相关。例如,nGragh 可以通过调用 NNP 库来支持英特尔 Nervana 神经网络处理器 (NNP)。XLA 可以通过直接生成二进制文件来支持 Google TPUs。MLIR 可以利用 XLA ÂĂŹS的编译能力。除了 TC 和 nGraph 之外,所有 DL 编译器都可以通过基于 LLVM 开发接口来支持自定义硬件目标。例如,Glow 使用自动代码生成技术(即基于 LLVM 的 ClassGen)来定义指令和节点,编译器研究人员可以调用接口来支持新的硬件目标。
支持的 DL 框架 目前 TensorFlow 和 PyTorch 是两个最流行的 DL 框架。支持DL框架的方法有三种:1) DL编译器集成到DL框架中;2) DL 框架已启动官方包以支持 DL 编译器;3) DL 编译器使用转换器部署 DL 模型。下面是说明这三种方法的示例。对于 1),XLA 与 TensorFlow 集成,而 TC 和 Glow 则与 PyTorch 和 Caffe2 提供轻量级集成。对于 2),PyTorch 将受益于直接利用编译器堆栈。为此,PyTorch 现在拥有基于 TVM 和 XLA 的官方软件包(即torch_tvm和torch_xla)。与 1) 和 2) 相比, 3) 更常见。例如,nGraph 通过使用”桥接”来维护其编程或用户界面,支持 TensorFlow 和 PadlePadle。TVM 可以部署 DL 框架生成的模型,然后优化模型推理的性能。随着越来越多的 DL 框架支持导出 ONNX 模型(第 2.1 节),DL 编译器支持 ONNX 进行未来开发非常重要。目前,三个DL编译器(即TVM、Glow和nGraph)能够加载、编译和执行预先训练的 ONNX 模型。
支持的代码目标 所有 DL 编译器都使用 LLVM 作为其低级 IR。与其他低级编译器(例如 GCC 和 ICC)相比,LLVM 的优势是统一IR、高模块化和快速自定义。借助 LLVM,编译器研究人员可以快速为特定于域的应用程序编写优化的通道,并通过 TableGen 模块生成各种目标代码(例如 ARM、x86、PTX)。如表 1 所示,ngraph 只能为 CPU 后端生成 LLVM 代码。CUDA 和 OpenCL 都用于实现异构并行计算。OpenCL 可用于对 NVIDIA 和 AMD GPU 进行编程,而 CUDA 特定于 NVIDIA GPU。尽管 OpenCL 承诺为 GPU 编程提供便携式语言,但其通用性可能会降低性能。两个 DL 编译器(即 TVM 和 XLA)支持同时生成 CUDA 和 OpenCL 代码。只有 TVM 和 PlaidML 支持生成 OpenGL 的代码,这是一个处理渲染图形的跨平台 API。然而,在WWDC 2018,苹果宣布弃用 OpenGL 和 OpenCL 的新系统。相反,Apple 使用金属 API 进行图形渲染和通用计算。目前只有 TVM 和 PlaidML 支持生成Metal代码。
支持的编译 所有 DL 编译器都支持实时编译 (JIT),以提高程序执行的效率。四个 DL 编译器(即 TVM、Glow、nGraph 和 XLA)支持提前编译 (AOT),其中 nGraph 仅在官方版本中启动 AOT(在 Beta 版本中不支持)。TVM/Relay 的 AOT 编译器生成给定中继表达式的本机库,并在 Python 中动态加载该库。Glow 可以生成提前编译的可执行捆绑包,这些捆绑包是自包含的编译网络模型,可用于在独立模式下执行。XLA使用 tfcompile 将 TensorFlow 图形编译为可执行代码
谷歌建议 JAX 支持 XLA,将 Autograd 和 XLA 组合在一起进行高性能机器学习研究,而不是添加自动区分(自动分级)支持。
支持的DL优化 至于low-bit inference,目前有四个DL编译器(即TVM、发光、nGraph和MLIR)支持量化。目前,单XLA无法解决量化问题:当重写的TensorFlow 图形减少到量化 XLA 图形时,量化重新编写器缺少部分。TVM 的自动分化、量化和training仍在开发中。此外,TVM v0.6 版本中还提供具有梯度支持的运算符计数。支持动态形状需要更改运行时,这对 DL 编译器来说是一个很大的挑战。此时,两个 DL 编译器(即 TVM 和 nGraph)支持动态形状。TC 和 XLA 仅支持内部静态尺寸,以提供自动形状和绑定推理。TVM 和 TC 支持自动调整,通过调整可用的映射选项来优化性能。TC 只能在 NVIDIA GPU 上执行自动调谐,而 TVM 可以对 CPU(x86 和 ARM)、移动 GPU 和 NVIDIA GPU应用自动fine tuen。TVM 和 TC 使用不同的调优方法:TC 使用遗传搜索,TVM 使用两种机器学习模型(即 GBT 和 TreeGRU)。PlaidML 只能对平铺(自动平铺)应用自动调整,它使用假设的成本模型探索切片大小的空间。
DL编译器的常见设计
设计概述
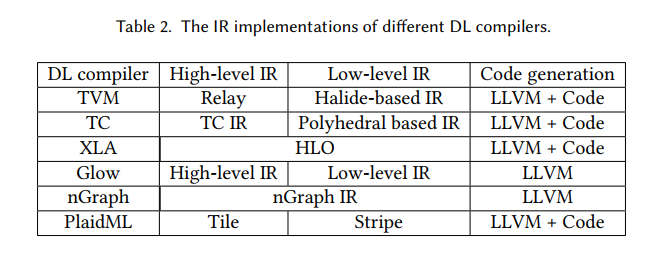
DL 编译器的常见设计主要包含两个部分:编译器前端和编译器后端,如图2所示。中间表示形式 (IR) 分布在前端和后端。通常,IR 是程序的抽象,用于程序优化。具体来说,DL模型在DL编译器中转换为多级IR,其中高级IR驻留在前端,低级IR驻留在后端。表2中列出了不同DL编译器中的IR实现。基于高级IR,编译器前端负责独立于硬件的转换和优化。基于低级IR,编译器后端负责特定于硬件的优化、代码生成和编译。DL编译器中的前端、后端和多级IR的功能简要描述如下:
The high-level IR 也叫graph IR 表示计算图和控制流,并且与硬件无关。high-level IR的设计挑战是计算和控制流的抽象能力,它能够捕获和表达不同的DL模型。高级 IR 的目标是建立运算符和数据之间的控制流和依赖关系,并为图形级优化提供接口。它还包含丰富的语义信息,用于编译,也为自定义运算符提供了可扩展性。第 4.2 节介绍了对高级别 IR 的详细讨论。
Low-level IR 用于针对不同硬件目标进行特定于硬件的优化和代码生成。因此,低级 IR 的细粒度应足以反映硬件特性并表示特定于硬件的优化。它还允许在编译器后端(如 Halide、多面体模型 和 LLVM)中使用成熟的第三方工具链。第 4.3 节介绍了对低级红外的详细讨论。
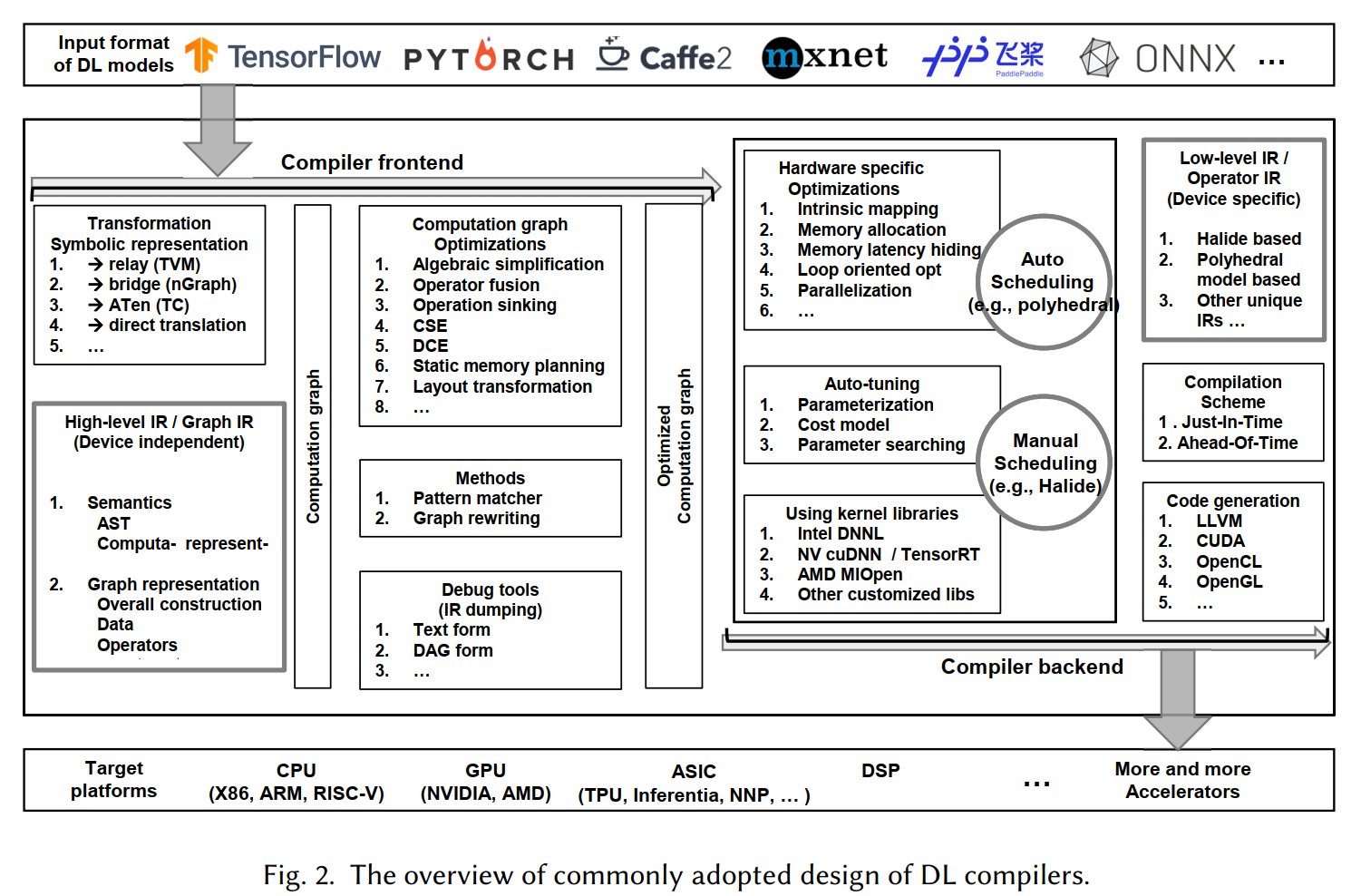
前端(The Frontend)将现有DL框架中的DL模型作为输入,然后将模型转换为计算图形表示形式(即graph IR)。为了支持不同框架中的各种格式,前端需要实现各种格式转换。计算图形优化结合了通用编译器和DL特定优化的优化技术,减少了冗余,提高了图形IR的效率。此类优化可分为节点级(例如,节点消除和零分量张量消除)、块级(例如代数简化、运算符融合和运算符下沉)和数据流级别(例如 CSE、DCE、静态内存规划和布局转换)。前端之后,将生成优化的计算图并传递到后端。请注意,某些 DL 编译器将进一步将优化的计算图转换为操作IR。第 4.4 节介绍了对前端的详细讨论。
后端(The Backend)将high-level IR转换为low-level IR,并同时执行特定于硬件的优化。一方面,它可以直接将high-level IR转换为第三方工具链(如 LLVM IR)以利用 LLVM 基础结构进行通用优化和 CPU/GPU 代码生成。另一方面,它可以利用 DL 模型和硬件特性的先前知识,通过自定义的编译过程生成更高效的代码。常用的硬件优化包括硬件内部映射、内存分配和提取、内存延迟隐藏、并行化和面向环路的优化。为了解决上述优化引入的大型解决方案空间,现有 DL 编译器广泛采用两种方法,如自动调度(例如多面体模型)和auto-tuning例如 AutoTVM)。优化的low-level IR使用 JIT 或 AOT 编译,以生成不同硬件目标的代码。第 4.5 节介绍了对后端的详细讨论。
High-Level IR
为了克服传统编译器中限制DL模型使用的复杂计算的IR限制,现有的DL编译器利用图IR与专门设计的数据结构进行高效的代码优化。为了更好地了解DL编译器中使用的图形IR,我们描述图形IR的语义和表示形式如下。

