
The use of Graphics Processing Units for rendering is well known, but their power for general parallel computation has only recently been explored. Parallel algorithms running on GPUs can often achieve up to 100x speedup over similar CPU algorithms, with many existing applications for physics simulations, signal processing, financial modeling, neural networks, and countless other fields.
This course will cover programming techniques for the GPU. The course will introduce NVIDIA’s parallel computing language, CUDA. Beyond covering the CUDA programming model and syntax, the course will also discuss GPU architecture, high performance computing on GPUs, parallel algorithms, CUDA libraries, and applications of GPU computing.
Problem sets will cover performance optimization and specific GPU applications such as numerical mathematics, medical imaging, finance, and other fields.
Goals for this week:
- How do we use cuBLAS to accelerate linear algebra computations with already optimized implementations of the
Basic Linear Algebra Subroutines (BLAS). - How can we use cuBLAS to perform multiple computations in parallel.
- Learn about the cuBLAS API and why it sucks to read.
- Learn to use cuBLAS to write optimized cuda kernels for graphics, which we will also use later for machine learning.
What is BLAS?
https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms
- BLAS defines a set of common functions we would want to apply to
scalars,vectors, andmatrices. - Libraries that implement it exist in almost all major languages.
- The names of these functions are opaque and hard to follow, so keeping an index nearby is useful. There are different functions for different number types
Some cuBLAS functions
cublasIsamax(): Is - a - max. finds the smallest (first) index in a vector that is a maximum for that vectorcublasSgemm(): generalized matrix matrix multiplication with single precision floats. Also how you do Vector Vector multiplication.cublasDtrmm(): triangular matrix matrix multiplication with double precision floats. See what I mean?
The symbols used throughout these slides will be consistent to the following:
- Scalars: 𝛂, 𝜷
- Vectors: 𝛘, 𝛄
- Matrices: A, B, C
BLAS (Basic Linear Algebra Subprograms) was written for FORTRAN and cuBLAS follows its conventions. Matrices are indexed column major.
There are 3 “levels” of functionality:
- Level 1: Scalar and Vector, Vector and Vector operations, 𝛄 → 𝛂𝛘 + 𝛄
- Level 2: Vector and Matrix operations, 𝛄 → 𝛂A𝛘 + 𝜷𝛄
- Level 3: Matrix and Matrix operations, C → 𝛂AB + 𝜷C
What is cuBLAS good for?
Anything that uses heavy linear algebra computations (on dense matrices) can benefit from GPU acceleration
- Graphics
- Machine learning (this will be covered next week)
- Computer vision
- Physical simulations
- Finance
- etc…..
The various cuBLAS types
All of the functions defined in cuBLAS have four versions which correspond to the four types of numbers in CUDA C
- S, s : single precision (32 bit) real float
- D, d : double precision (64 bit) real float
- C, c : single precision (32 bit) complex float (implemented as a float2)
- Z, z : double precision (64 bit) complex float
- H, h : half precision (16 bit) real float
cuBLAS function types
cublasSgemm → cublas S gemm
- cublas : the prefix
- S : single precision real float
- gemm : general matrix-matrix multiplication
cublasHgemm
- Same as before except half precision
cublasDgemv → cublas D gemv
- D : double precision real float
- gemv : general matrix vector multiplication
Numpy vs math vs cuBLAS
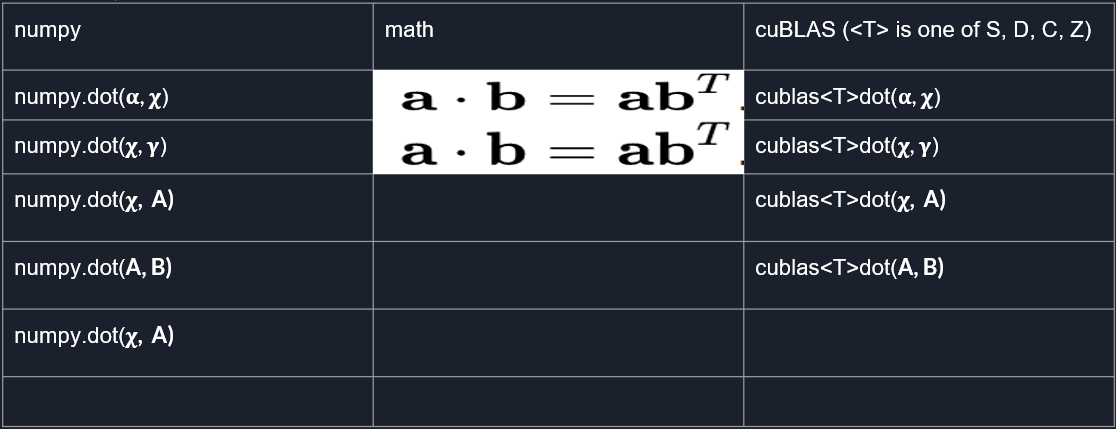
Error Checking
- Like CUDA and cuFFT, cuBLAS has a similar but slightly different status return type.
cublasStatus_t- We will use a similar macro to gpuErrchk and the cuFFT version to check for cuBLAS errors.
Streaming Parallelism
- Use
cudaStreamCreate()to create a stream for computation. - Assign the stream to a cublas library routine using
cublasSetStream() - When you call the routine it will operate in parallel (asynchronously) with other streaming cublas calls to maximize parallelism.
- Should pass your constant scalars by reference to help maximize this benefit.
Cublas Example
1 | #include <stdio.h> |

