
The use of Graphics Processing Units for rendering is well known, but their power for general parallel computation has only recently been explored. Parallel algorithms running on GPUs can often achieve up to 100x speedup over similar CPU algorithms, with many existing applications for physics simulations, signal processing, financial modeling, neural networks, and countless other fields.
This course will cover programming techniques for the GPU. The course will introduce NVIDIA’s parallel computing language, CUDA. Beyond covering the CUDA programming model and syntax, the course will also discuss GPU architecture, high performance computing on GPUs, parallel algorithms, CUDA libraries, and applications of GPU computing.
Problem sets will cover performance optimization and specific GPU applications such as numerical mathematics, medical imaging, finance, and other fields.
Lecture 4 GPU Memory Systems
Latency and Throughput
- Latency is the delay caused by the physical speed of the hardware
- Throughput is the maximum rate of production/processing
For CPU: CPU = low latency, low throughput
- CPU clock = 3 GHz (3 clocks/ns)
- CPU main memory latency: ~100+ ns
- CPU arithmetic instruction latency: ~1+ ns
For GPU:
- GPU = high latency, high throughput
- GPU clock = 1 GHz (1 clock/ns)
- GPU main memory latency: ~300+ ns
- GPU arithmetic instruction latency: ~10+ ns
Above numbers were for Kepler GPUs (e.g. GTX 700 series)
For Fermi, latencies tend to be double that of Kepler GPUs
Compute & IO Throughput
GeForce GTX Titan Black (GK110 based)
| Compute throughput | 5 TFLOPS (single precision) |
|---|---|
| Global memory bandwidth | 336 GB/s (84 Gfloat/s) |
- GPU is very IO limited!
IOis very often the throughput bottleneck, so its important to be smart about IO. - If you want to get beyond ~900 GFLOPS, need to do multiple FLOPs per shared memory load.
1 | TFLOP = Teraflop; a way of measuring the power of a computer based on mathematical capability. (Capability of a processor to calculate one trillion floating-point operations per second) |
GPU Memory Systems
Cache
A cache is a chunk of memory that sits in between a larger pool of memory and the processor
- Often times implemented at hardware level
- Has much faster access speed than the larger pool of memory
When memory is requested, extra memory near the requested memory is read into a cache
- Amount read is cache and memory pool specific
Regions of memory that will always be cached together are calledcache lines - This makes future accesses likely to be found in the cache
Such accesses are calledcache hitsand allow much faster access
If an access is not found in the cache, it’s called acache miss(and there is obviously no performance gain)
GPU Memory Breakdown

- Registers: Fast, only for one thread. The fastest form of memory on the multi-processor. Is only accessible by the thread. Has the lifetime of the thread.
- Local memory: For what doesn’t fit in registers, slow but cached, one thread. Resides in global memory and can be 150x slower than register or shared memory. Is only accessible by the thread. Has the lifetime of the thread.
- Global memory: Slow and uncached, all threads. Potentially 150x slower than register or shared memory – watch out for uncoalesced reads and writes. Accessible from either the host or device. Has the lifetime of the application—that is, it persistent between kernel launches.
- Shared memory: Fast, bank conflicts; limited; threads in block. Can be as fast as a register when there are no bank conflicts or when reading from the same address. Accessible by any thread of the block from which it was created. Has the lifetime of the block.
- L1/L2/L3 cache
- Constant memory: (read only) Slow, cached, all threads
- Texture memory: (read only) Cache optimized for 2D access, all threads
- Read-only cache (CC 3.5+)

Global Memory
Global memory is separate hardware from the GPU core (containing SM’s, caches, etc).
- The vast majority of memory on a GPU is global memory
- If data doesn’t fit into global memory, you are going to have process it in chunks that do fit in global memory.
- GPUs have .5 - 24GB of global memory, with most now having ~2GB.
Global memory latency is ~300ns on Kepler and ~600ns on Fermi
Green box is GK110, red lines are global memory
Accessing global memory efficiently
Global memory IO is the slowest form of IO on GPU except for accessing host memory (duh…)
Because of this, we want to access global memory as little as possible
Access patterns that play nicely with GPU hardware are called coalesced memory accesses.
Coalesced memory accesses minimize the number of cache lines read in through these memory transactions. GPU cache lines are 128 bytes and are aligned.
Misalignment can cause non-coalesced access:
A coalesced access: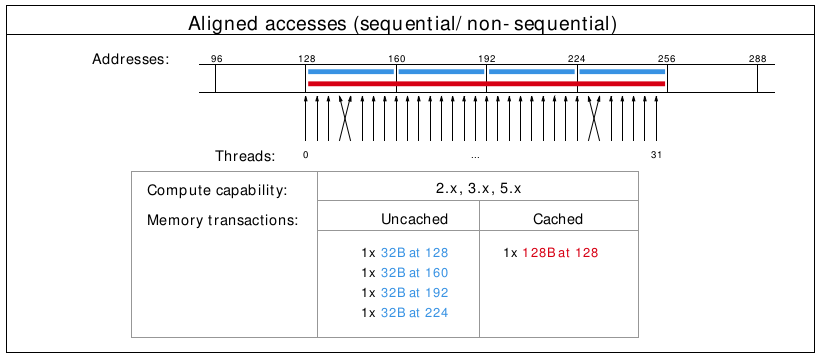
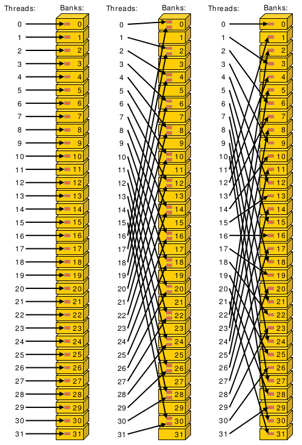
Bank conflicts
Shared memory is setup as 32 banks
- If you divide the shared memory into 4 byte-long elements, element i lies in bank i % 32.
A bank conflict occurs when 2 threads in a warp access different elements in the same bank.
Bank conflicts cause serial memory accesses rather than parallel
Serial anything in GPU programming = bad for performance
Bank conflict examples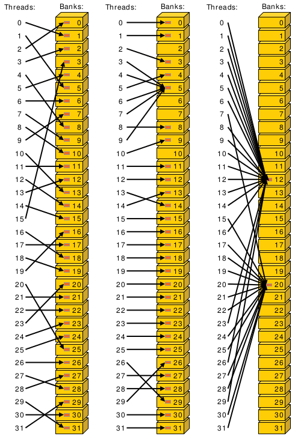
L1 Cache
- Fermi - caches local & global memory
- Kepler, Maxwell - only caches local memory
- same hardware as shared memory
- Nvidia used to allow a configurable size (16, 32, 48KB), but dropped that in recent generations
- each SM has its own L1 cache
L2 Cache
- caches all global & local memory accesses
- ~1MB in size
- shared by all SM’s
L3 Cache
- Another level of cache above L2 cache
- Slightly slower (increased latency) than L2 cache but also larger.
Constant Memory
- Constant memory is global memory with a special cache
Used for constants that cannot be compiled into program
Constants must be set from host before running kernel.
~64KB for user, ~64KB for compiler - kernel arguments are passed through constant memory
Lecture 5: Synchronization and ILP
Synchronization
Ideal case for parallelism:
- no resources shared between threads
- no communication needed between threads
However, many algorithms that require shared resources can still be accelerated by massive parallelism of the GPU.
On a CPU, you can solve synchronization issues using Locks, Semaphores, Condition Variables, etc.
On a GPU, these solutions introduce too much memory and process overhead. We have simpler solutions better suited for parallel programs
Use the __syncthreads() function to sync threads within a block
- Only works at the block level
SMs are separate from each other so can’t do better than this - Similar to barrier() function in C/C++
- This
__synchthreads()call is very useful for kernels using shared memory.
Atomic Operations
Atomic Operations are operations that ONLY happen in sequence.
For example, if you want to add up N numbers by adding the numbers to a variable that starts in 0, you must add one number at a time. Don’t do this though. We’ll talk about better ways to do this in the next lecture. Only use when you have no other options.
CUDA provides built in atomic operations: Use the functions: atomic<op>(float *address, float val);
- Replace
with one of: Add, Sub, Exch, Min, Max, Inc, Dec, And, Or, Xor. e.g. atomicAdd(float *address, float val) for atomic addition - These functions are all implemented using a function called atomicCAS(int *address, int compare, int val).
- CAS stands for compare and swap. The function compares *address to compare and swaps the value to val if the values are different
Instruction Level Parallelism (ILP)
Instruction Level Parallelism is when you avoid performances losses caused by instruction dependencies
- Idea: we do not have to wait until instruction n has finished to start instruction n + 1
- In CUDA, also removes performances losses caused by how certain operations are handled by the hardware
ILP Example: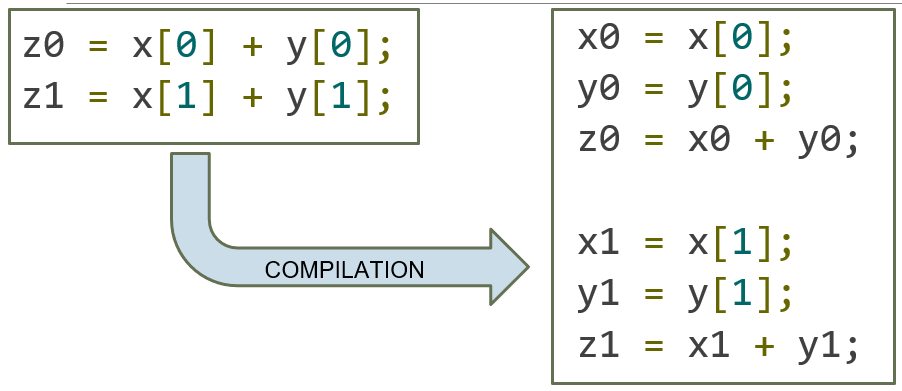
The second half of the code can’t start execution until the first half completes
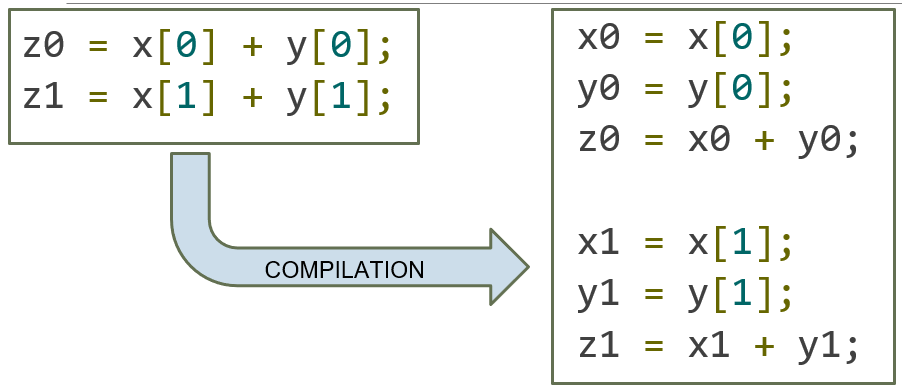
- Sequential nature of the code due to instruction dependency has been minimized.
- Additionally, this code minimizes the number of memory transactions required

