
This example using existing Linear Interpolation (aka lerp) operator, but same guidelines apply for other operators (new and existing ones).
As all changes going to impact performance significantly, we can use the simplest benchmark to measure operator speed before updates and establish the baseline.
1 | y = torch.randn(1000000) |
Simple implementation
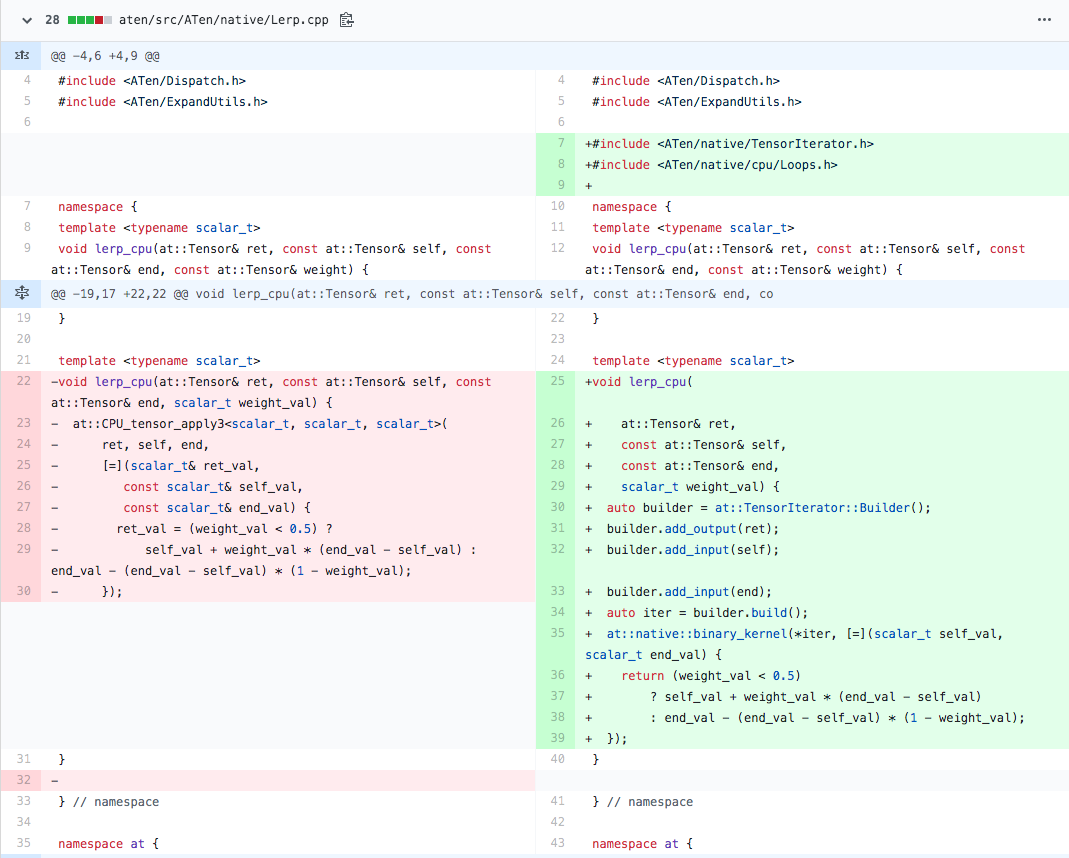
As the first step, we are naively introducing TensorIterator to replace CPU_tensor_apply3 (it is considered the lousy pattern to use cpu/Loops.h anywhere but in cpu/ subfolder, but we will return to it later in this doc).
Update: binary_kernel recently was replaced by more universal cpu_kernel, they have exact same API.
code: https://github.com/pytorch/pytorch/pull/21025/commits/c5593192e1f21dd5eb1062dbacfdf7431ab1d47f
In compare to TH_APPLY_* and CPU_tensor_apply* and solutions, TensorIterator usage is separated by two steps.
- Defining iterator configuration with the TensorIterator::Builder. Under the hood, builder calculates tensors shapes and types to find the most performant way to traverse them (https://github.com/pytorch/pytorch/blob/dee11a92c1f1c423020b965837432924289e0417/aten/src/ATen/native/TensorIterator.h#L285)
- Loop implementation. There are multiple different kernels in Loops.h depending on the number of inputs, they dispatch automatically by cpu_kernel, the ability to do parallel calculations, vectorized version availability (cpu_kernel_vec), type of operation (vectorized_inner_reduction). In our case, we have one output and two inputs, in this type of scenario we can use cpu_kernel. TensorIterator automatically picks the best way to traverse tensors (such as taking into account contiguous layout) as well as using parallelization for bigger tensors.
As a result, we have a 24x performance gain.
1 | In [*2*]: x = torch.randn(1000000) |
Most of the gain comes from the parallelization, so it is worth checking with OMP_NUM_THREADS=1.
Here we can see 2x improvement in comparison to the CPU_tensor_apply3 version of the code.
1 | In [*2*]: x = torch.randn(1000000) |
Using native/cpu
However, as noted above, it is sub-optimal (and NOT recommended solution) as we are not using vectorization and various compile-time optimizations. We can fix it by moving code into the native/cpu folder.
// Content of the aten/src/ATen/native/cpu/LerpKernel.cpp1
1 | #include <ATen/ATen.h> |
code: https://github.com/pytorch/pytorch/pull/21025/commits/bcf9b1f30331fc897fcc94661e84d47e91bf7290
This code using the same type dispatch pattern AT_DISPATCH_FLOATING_TYPES, but moving everything into the kernel code for better optimization.
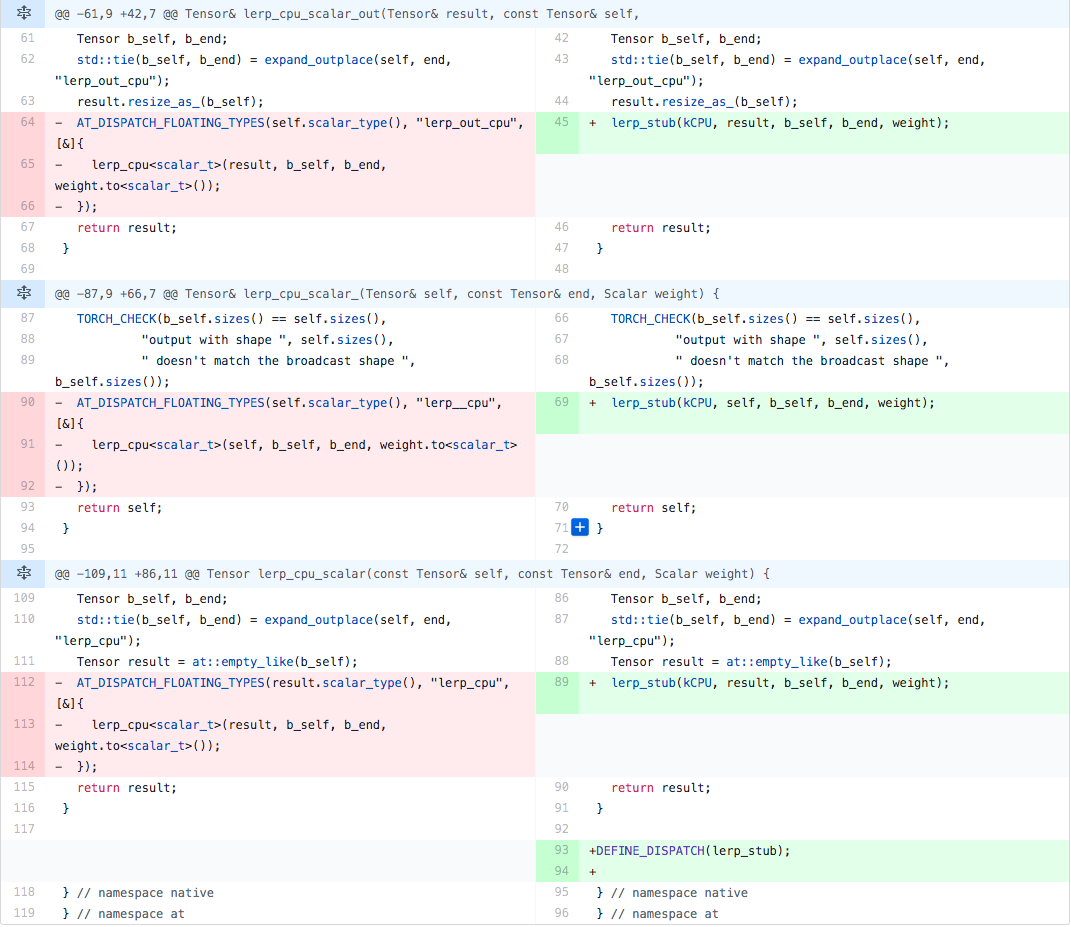
Such code organization gives us 2x performance boost in comparison to the previous naive implementation. This optimization is archived by compiling AVX2 kernel versions (only applies to native/cpu folder) and dispatching supported code based on cpuinfo.
Multithreaded
1 | In [*2*]: x = torch.randn(1000000) |
Single thread
1 | In [*2*]: x = torch.randn(1000000) |
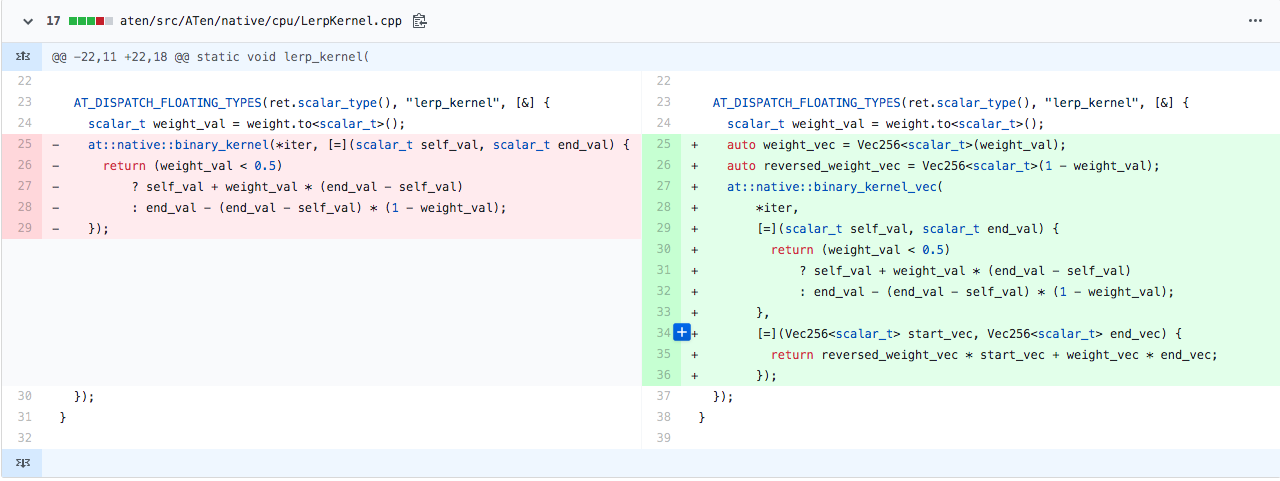
Vectorization with the cpu_kernel_vec
In many cases, we can also benefit from the explicit vectorization (provided by Vec256 library). TensorIterator provides the easy way to do it by using _vec loops.
code: https://github.com/pytorch/pytorch/pull/21025/commits/83a23e745e839e8db81cf58ee00a5755d7332a43
We are doing so by replacing the cpu_kernel with the cpu_kernel_vec. At this particular case, weight_val check was omitted (to simplify example code), and performance benchmark show no significant gain.

