
本篇文章来总结下业界有名的计算机深度学习方向的大佬们。引用最权威的资料来,学术界公认的h-index排名。所谓H-index,就是high citations,简单来说就是论文被引用的频次。
H-index排名前十的计算机科学家
下图是2018年计算机科学领域的H-index排名前十,相信从中就是小白们也能看到不少熟悉的名字。完整名单
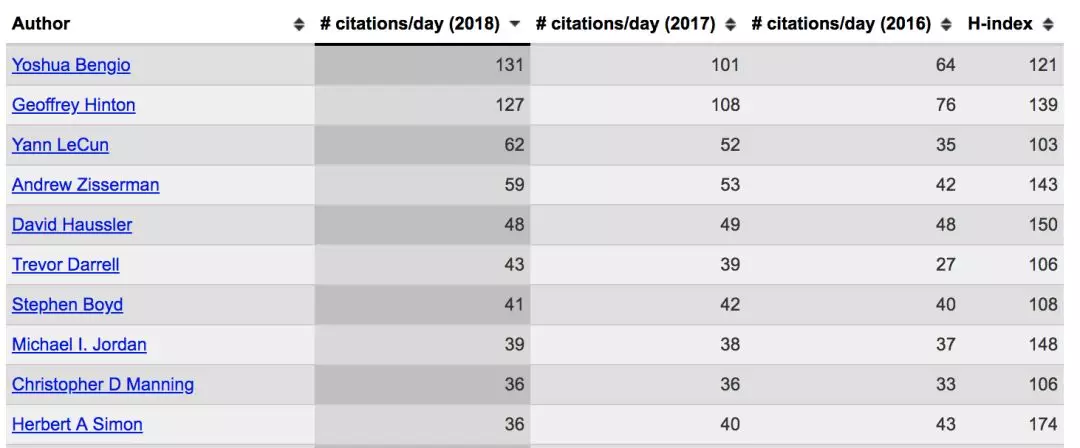
H-index排名越高说明论文被人引用的越频繁,在学术界来说这就意味着影响力。下面我们来了解一下排名前十的大佬们都是谁,做过什么。
Yoshua Bengio
加拿大计算机科学家,深度学习三巨头之一,LeNet5作者之一,花书《Deep learning》作者之一,一直呆在学术界。

代表性文章:
1 LÉcun, Yann, et al. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE, vol. 86, no. 11, 1998, pp. 2278–2324.
[2] Bengio Y, Courville A C, Vincent P, et al. Representation Learning: A Review and New Perspectives[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1798-1828.
Geoffrey Hinton
加拿大认知心理学家和计算机科学家,深度学习三巨头之一,反向传播算法提出者之一,2006年在science期刊发表深层网络逐层初始化训练方法,揭开深度学习世纪新序幕,其弟子Alex Krizhevsky提出AlexNet网络。

代表性文章:
1 Rumelhart D E , Hinton G E , Williams R J . Learning internal representations by error propagation[M]// Neurocomputing: foundations of research. MIT Press, 1988.
[2] Hinton G E, Salakhutdinov R. Reducing the dimensionality of data with neural networks.[J]. Science, 2006, 313(5786): 504-507.
[3] Krizhevsky A , Sutskever I , Hinton G . ImageNet Classification with Deep Convolutional Neural Networks[C]// NIPS. Curran Associates Inc. 2012.
Yann LeCun
法国计算机科学家,深度学习三巨头之一,Facebook首席人工智能科学家,LeNet5网络第一作者,深度学习综述《Deep learning》作者之一。

至此三巨头都出现了,不愧是三巨头,它们之间也有着千丝万缕的合作,从上面同时出现在LeNet5和深度学习花书的Yoshua Bengio和Yann LeCun就可以看出,两人年纪也相当,而Hinton其实已经是两者的老师级别。
Andrew Zisserman
英国计算机科学家,牛津大学教授,计算机视觉研究员,经典书《Multiple View Geometryin Computer Vision》作者,VGG网络作者之一,Pascal Visual Object Classes (VOC) Challenge发起者之一,Deep Mind研究员。

代表性文章:
1 Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. international conference on learning representations, 2015.
[2] Everingham M, Van Gool L, Williams C K, et al. The Pascal Visual Object Classes (VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[3] Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks[J]. neural information processing systems, 2015: 2017-2025.
David Haussler
美国生物信息学家,霍华德休斯医学研究所研究员、生物分子工程教授等,人类基因组计划竞赛中组装了第一个人类基因组序列。

代表性文章:
1 Lander E S, Linton L, Birren B, et al. Initial sequencing and analysis of the human genome.[J]. Nature, 2001, 409(6822): 860-921.
Trevor Darrell
加州大学伯克利分教授,伯克利人工智能研究(BAIR)实验室的联合主任,Caffe,RCNN作者之一。

代表性文章:
1 Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional Architecture for Fast Feature Embedding[J]. acm multimedia, 2014: 675-678.
[2] Girshick R B, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. computer vision and pattern recognition, 2014: 580-587.
StephenP.Boyd
三星工程教授,斯坦福大学信息系统实验室电气工程教授,凸优化书籍《Convex optimization》作者。

代表性文章:
1 Stephen Boyd L V, Stephen Boyd L V. Convex optimization[J]. IEEE Transactions on Automatic Control, 2006, 51(11):1859-1859.
[2] Candes E J, Wakin M B, Boyd S P. Enhancing Sparsity by Reweighted l(1) Minimization[J]. Journal of Fourier Analysis & Applications, 2007, 14(5):877-905.
Michael I. Jordan
美国科学家、加州大学伯克利分校教授。机器学习领域的领军人物之一,2016年《科学》杂志评定的世界上最具影响力的计算机科学家。Latent Dirichlet Allocation模型作者。

代表性文章:
1 Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2012, 3:993-1022.
Christopher Manning
斯坦福大学人工智能实验室主任,语言学和计算机科学家。书籍《Introduction to information retrieval》,《Foundations of Statistical Natural Language Processing》作者。

代表性文章:
1 Manning C D. Foundations of statistical natural language processing[M]// Foundations of Statistical Natural Language Processing. 1999.
[2] Larson R R. Introduction to Information Retrieval[J]. Journal of the Association for Information Science and Technology, 2010, 61(4): 852-853.
Herbert A Simon
诺贝尔经济学奖,图灵奖等获得者,书籍《The Sciences of the Artificial》,《Human Problem Solving》作者,也是唯一一个已经不在世近二十年的科学家,却还能在过去一年的论文引用前十中占据一席,可见影响力之大。

代表论文:

除了上面的10位,计算机科学领域还有很多世界级的研究人员值得我们去关注的,比如花书作者之一和生成对抗网络的提出者Ian Goodfellow等,不再过多介绍。
深度学习领域的优秀青年华人
如果说世界级科学家离我们太遥远,那么身边优秀的华人是不是需要好好关注?下面介绍几个优秀的80后青年华人,都是非常有代表性的人物,对深度学习有突破性的学术贡献或开源框架作者。
何恺明
本科就读于清华大学,博士毕业于香港中文大学多媒体实验室,曾在微软亚洲研究院担任实习生,目前在Facebook人工智能实验室(FAIR)担任研究科学家。他是Resnet、Mask R-CNN第一作者,也是首位获计算机视觉领域三大国际会议之一CVPR“最佳论文奖”的中国学者。另外他也获得了CVPR 2016和ICCV 2017(Marr Prize)的最佳论文奖,并获得了ICCV 2017最佳学生论文奖,CVPR 2018的PAMI年轻学者奖,这就是别人隔壁家的小明和学霸。

代表性文章:
1 He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. 2015.
[2] He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
贾扬青
深度学习框架Caffe之父。本科和硕士研究生就读于清华大学,博士毕业于加州大学伯克利分校,曾在新加坡国立大学、微软亚洲研究院、NEC美国实验室、Google Brain工作,任Facebook研究科学家,负责前沿AI平台的开发以及前沿的深度学习研究。现已入职阿里巴巴。

代表性文章:
1 Jia Y , Shelhamer E , Donahue J , et al. Caffe: Convolutional Architecture for Fast Feature Embedding[J]. 2014.
[2] Decaf: A deep convolutional activation feature for generic visual recognition
如果说何凯明是学术界的青年扛把子,那么贾扬清就是工业界的青年扛把子了,他还有知乎账号,冒过几个泡。
李沐
2008年本科毕业于上海交通大学计算机系,CMU博士毕业,深度学习开源框架MXNet作者之一,曾在微软亚洲研究院担任实习生,在亚马逊就职。沐神有一本在线书籍《动手学深度学习》,另外现在有很多的群,算是做深度学习的普及工作贡献了。

代表性文章:
1 Li M , Liu Z , Smola A J , et al. DiFacto - Distributed Factorization Machines[C]// Acm International Conference on Web Search & Data Mining. ACM, 2016.
陈天奇
本科毕业于上海交通大学ACM班,华盛顿大学计算机系博士生。深度学习编译器TVM,SVDFeature,XGBoost,cxxnet等作者,MxNet,DMLC发起人之一。

代表性文章:
1 MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, Zheng Zhang
LearningSys at Neural Information Processing Systems 2015
[2] TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, Arvind Krishnamurthy
韩松
本科毕业于清华大学后,博士毕业于斯坦福大学,深鉴科技联合创始人之一,2016年ICLR最佳论文deep compression论文一作。就放深鉴科技四个创始人的照片吧,都是青年才俊。

代表性文章:
1 Han S , Kang J , Mao H , et al. ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA[J]. 2016.
[2] Han S, Mao H, Dally W J, et al. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding[J]. international conference on learning representations, 2016.

