
Horovod是Uber(优步)开源的又一个深度学习工,Horovod在2017年10月,Uber以Apache 2.0授权许可开源发布。Horovod是优步跨多台机器的分布式训练框架,现已加入开源计划LF Deep Learning Foundation。
Uber利用Horovod来支持自动驾驶汽车,欺诈检测和出行预测。该项目的贡献者包括亚马逊,IBM,英特尔和Nvidia。除了优步,阿里巴巴,亚马逊和Nvidia也在使用Horovod。Horovod项目可以与TensorFlow,Keras和PyTorch等流行框架一起使用。优步于上个月加入了Linux基金会,并加入了其他科技公司,如AT&T和诺基亚,他们出面支持LF Deep Learning Foundation开源项目。LF深度学习基金会成立于3月,旨在支持深度学习和机器学习的开源项目,并且是Linux基金会的一部分。在推出Acumos(用于训练和部署AI模型)和Acumos Marketplace(AI模型的开放式交易所)推出一个月后,Horovod正式推出。自该基金会启动以来,开展的其他项目包括机器学习平台Angel and Elastic Deep Learning,该项目旨在帮助云服务提供商利用TensorFlow等框架制作云集群服务。百度和腾讯分别于八月份加入这些项目,它们也是LF深度学习基金会的创始成员。
深度学习到底是如何训练数据的?
深度学习训练的算法叫做反向传播。即通过神经网络得到预测结果,把预测结果跟标注Label进行比对,发现误差;然后得到神经网络里每个神经元权重导数;接着通过算法得到每个神经元导数,再更新神经元的权重以得到更好的神经元网络,周而复始迭代训练,使得误差减少。
神经网络推理能力随着规模、复杂度增加,能力会极大的增强。但从计算能力角度来说又出现了新问题:很多时候大规模神经网络很难在单个/单点计算单元里面运行,这会导致计算很慢,以至无法运行大规模数据。所以人们提出两种深度学习的基本方法以解决这个问题。
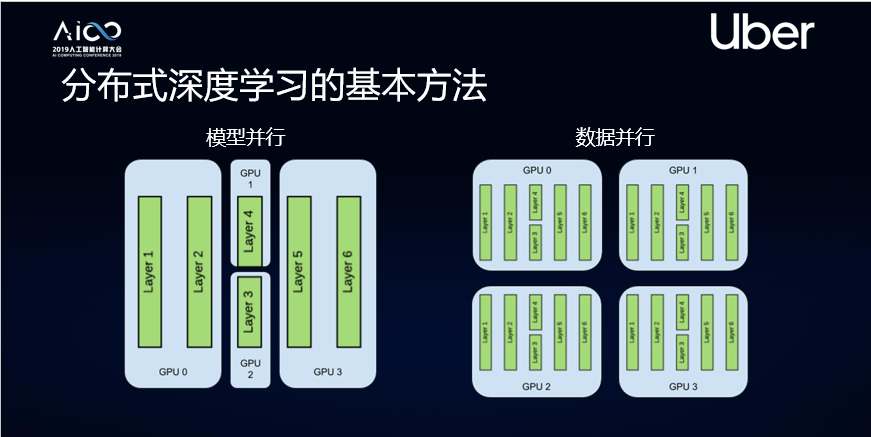
深度学习的两种基本方法
第一种是模型并行。即把复杂的神经网络拆分,分布在计算单元或者GPU里面进行学习,让每个GPU同步进行计算。这个方法通常用在模型比较复杂的情况下。
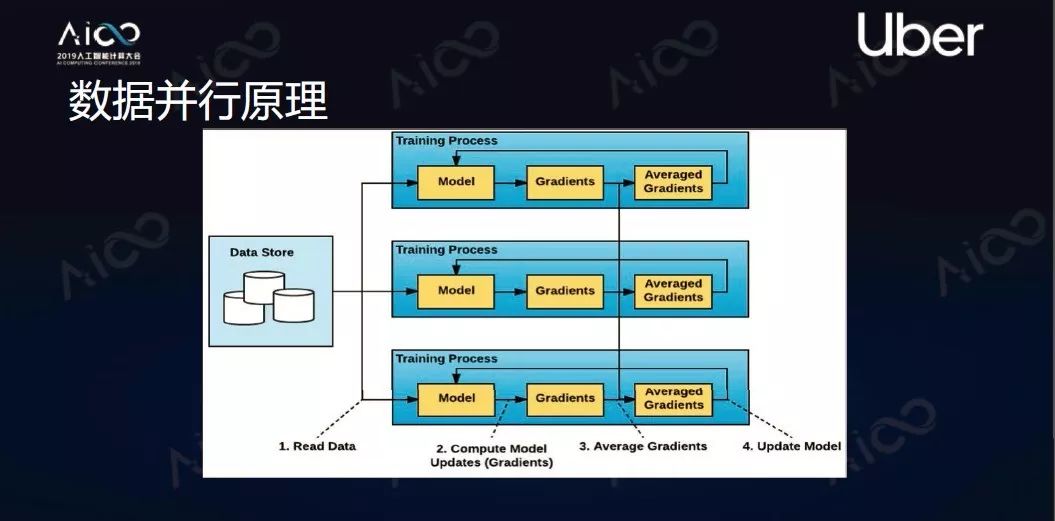
另一种是数据并行。即让每个机器里都有一个完整模型,然后把数据切分成n块,把n块分发给每个计算单元,每个计算单元独自计算出自己的梯度。同时每个计算单元的梯度会进行平均、同步,同步后的梯度可以在每个节点独立去让它修正模型,整个过程结束后每个节点会得到同样的模型。这个方法可以让能够处理的数据量增加,变成了原来的n倍。
白话版走心解读:深度学习的这两种基本方法之前提及过。简单说就是一个拆模型,一个拆数据,但目标相同:让运算更高效。这里可以让上面提及的“梯度”先来混个脸熟。
首先“梯度下降”是深度学习优化的一种方法。很好理解,就是说它可以更好地训练模型。那“梯度下降”为什么可以实现优化呢?
我们可以把神经网络理解成一个非常复杂的函数,包含数百万个参数。这些参数代表的是一个问题的数学解答。实质上,训练神经网络=最小化一个损失函数。而“梯度下降”可以帮助我们找到那个最小化的损失函数。好了,先到这里……
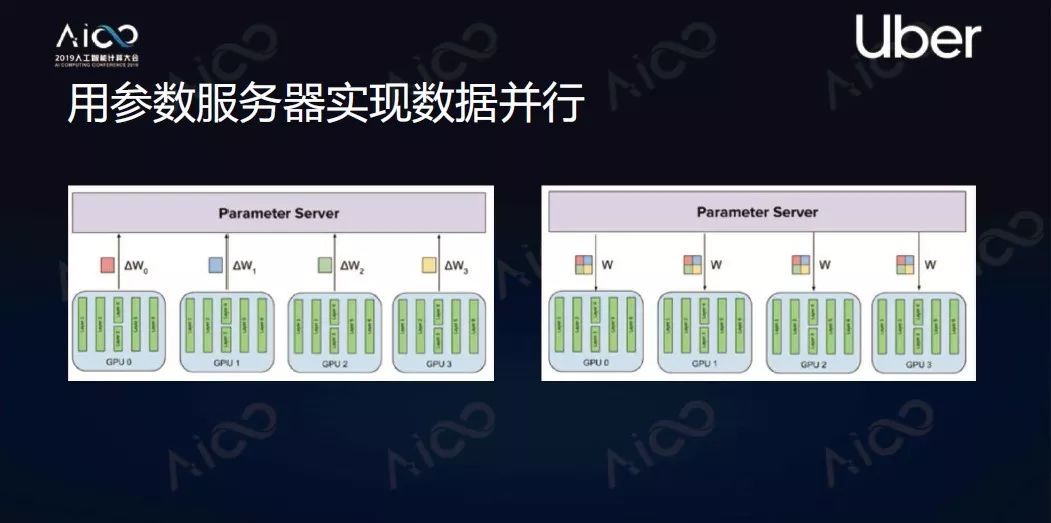
实现“数据并行”的两种工程方法
参数服务器(Parameter Server)。
在计算单元以外加设新的服务器叫做参数服务器。每次训练的时候每个计算单元把梯度发送给参数服务器,服务器把他们进行汇总计算平均值,把平均值返回到每个计算单元,这样每个计算单元就同步了。
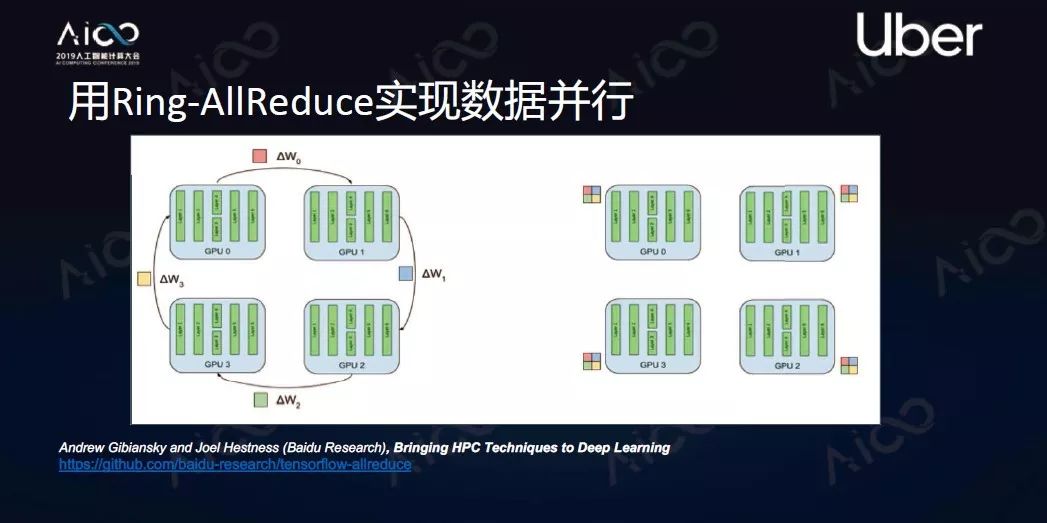
Ring-AllReduce
它是从高性能计算集合通信找到的想法。做法是把每个计算单元构建成一个环,要做梯度平均的时候每个计算单元先把自己梯度切分成N块,然后发送到相邻下一个模块。现在有N个节点,那么N-1次发送后就能实现所有节点掌握所有其他节点的数据。这个方法被证明是一个带宽最优算法。
白话版走心解读:“工程做法”其实就是实现方法。(另外再敲个黑板!使用多个GPU卡训练同一个深度学习任务就是分布式计算)再过几天就十一了,我们不妨借着祖国70年华诞举个栗子。这里讲的数据并行的两种实现办法,可以这样理解。
学校舞蹈团想排一支集体舞庆祝华诞。由于报名火爆,入选人员超出预期。于是领队由1人增加为2人,便于管理庞大的团员,这个便是“参数服务器”方法,以增加“领队”的方式提升管理数据的效率;还有一种是,取消领队,大家彼此监督,发挥集体各成员的最大脑力,这个就是“Ring-All Reduce”,以取消“领队”的方式降低沟通成本并且激发成员最大潜力。这样来看,两者优劣势就清晰了。
参数服务器的做法理论容错性比较强,因为每个节点相互之间没有牵制,互相没有关联,它只是需要跟参数服务器本身进行通信,就可以运作了。缺点是有额外的网络开销,扩展效率会受到影响。
Ring-AllReduce优点非常明显,性能非常好,如果在大规模分布式训练时候资源利用率相当高,网络占用是最优的。它的缺点是在工程上的缺点,容错性较差,很多实现都是用MPI实现(MP本身并不是为容错设计的,它更偏向于照顾高性能的计算)。
Horovod是什么
Horovod是基于Ring-AllReduce方法的深度分布式学习插件,以支持多种流行架构包括TensorFlow、Keras、PyTorch等。这样平台开发者只需要为Horovod进行配置,而不是对每个架构有不同的配置方法。
白话版走心解读:Horovod的名字来源于俄罗斯的民族舞蹈,跳舞者手牵手围成一个圈。给它命名的人是位俄罗斯工程师,因为他觉得这个架构看起来很像在“转圈”。
很形象,我们可以看出它是基于Ring-AllReduce方法进行开发的;而另一方面我们也可以窥见,看似只是生活在枯燥艰涩的代码世界的程序员们,自有着独特的浪漫。
Horovod 如何使用
首先认识一下Keras单机训练脚本。
第一步用Keras定义它的model;第二步X-train、Y-train,定义训练样本和测试样本;第三步optimizer,即选定优化器;第四步model.compile;最后是model. fit。这样就可以开始训练了,这是Keras训练脚本骨干。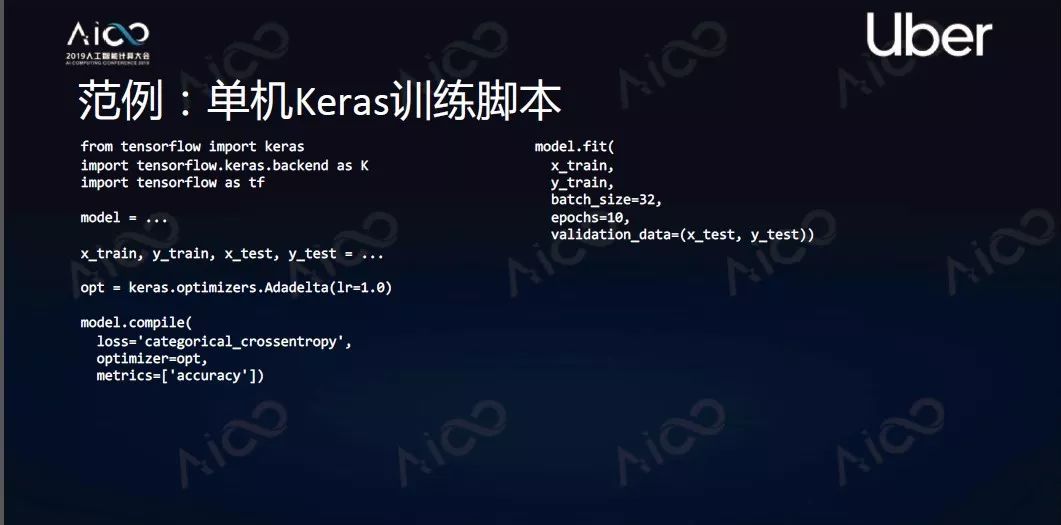
接下来就是怎样把单机训练脚本跟Horovod结合变成多机训练脚本、分布式训练脚本。
第一,在代码里引入Horovod库,做初始化;第二,定义优化器的时候,优化器重要参数是学习率;第三,用一个对象把原来优化器包起来,这就是抽象了Horovod需要进行的梯度平均的逻辑,会比较容易使用;第四,让Horovod把每次训练的初始状态广播到每个节点,这样保证每个节点从同一个地方开始;第五,训练的长度,由于把训练分布在N个机器上了,所以可以极大减小,除以N就可以了。
黄色是添加的代码或者要修改的地方
总结一下,把单个计算单元训练变成多机分布式训练用Horovod是非常简单的,只需要做三步。第一步程序引入Horovod稍微做修改,调整学习率、时间;第二步处理训练的数据,进行分布化;第三步用Horovodrun程序进行启动,就可以进行分布式训练了。
Horovod 使用案例
美国橡树岭国家实验室在全球最快的超级计算机Summit上,用Horovod进行像素级高清气象云图分析,去年获得了ACN Gordon Bell Prize。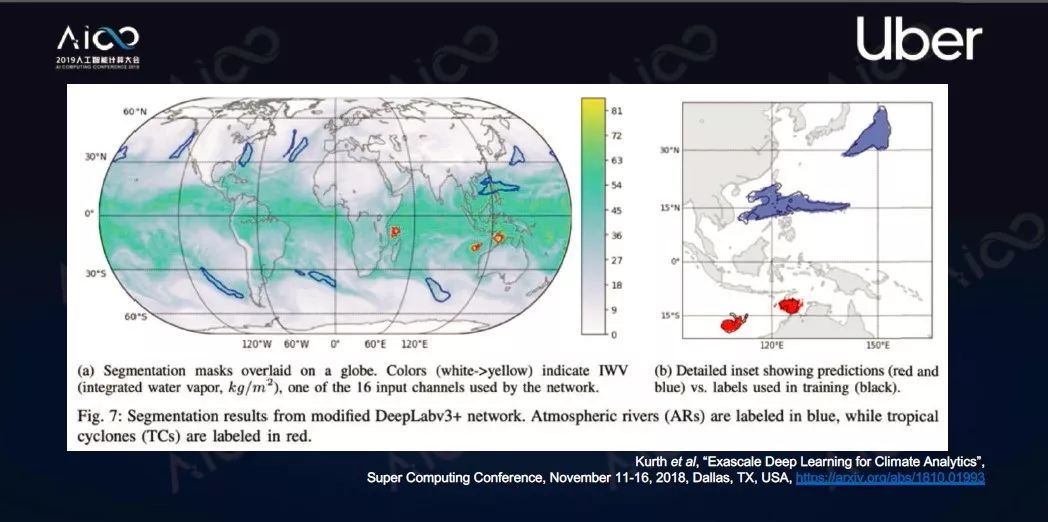
这是世界上首次突破Exaops,即每秒一百亿亿次的深度学习应用,峰值计算达1.13 EF/S,持续计算999.0 PF/S。什么概念呢?2017年得奖是中国在太湖之光做的地震仿真的项目,这个项目持续计算是18.9个Exaops,上面有4560节点,每个节点上有6个GPU,有27360 Volta GPU,用到了Horovod高级功能分级化AllReduce、Tensor融合、16位浮点数,90.7%扩展效率。
ORNL一份声明称,Summit超级计算机在一秒钟时间内完成的计算任务,能让全世界所有人不吃不喝,不休不眠地以每秒1次的计算速度连续算上306天。如果只交给1个人来计算的话,那么就算太阳燃料耗尽,然后超新星爆炸,地球被毁灭,这个人都不会算完,因为这个计算过程需要63.4亿年,然而我们太阳系却只有50亿年寿命。

