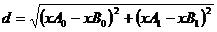deffile2matrix(filename): fr = open(filename) numberOfLines = len(fr.readlines()) #get the number of lines in the file returnMat = zeros((numberOfLines,3)) #prepare matrix to return classLabelVector = [] #prepare labels return fr = open(filename) index = 0 type={'largeDoses':3,'smallDoses':2,'didntLike':1} for line in fr.readlines(): line = line.strip() listFromLine = line.split('\t') returnMat[index,:] = listFromLine[0:3] classLabelVector.append(type.get(listFromLine[-1],0)) index += 1 return returnMat,classLabelVector
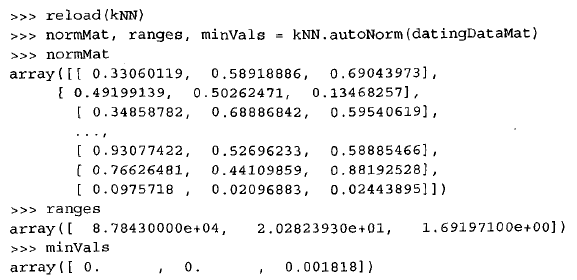
defdatingClassTest(): hoRatio = 0.50#hold out 10% datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] numTestVecs = int(m*hoRatio) errorCount = 0.0 for i inrange(numTestVecs): classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) print"the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]) if (classifierResult != datingLabels[i]): errorCount += 1.0 print"the total error rate is: %f" % (errorCount/float(numTestVecs)) print errorCount
2.2.5 使用算法:构建完整可用系统
约会网站预测函数:
1 2 3 4 5 6 7 8 9 10
defclssifyPerson(): resultList = ['not at all','in small doses','in large doses'] percentTats = float(raw_input("percentage of time spent playing video games?")) ffmiles = float(raw_input("frequent fliter miles earned per year?")) iceCream = float(raw_input("liters of ice cream consumed per year?")) datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') normMat,ranges,minVals = autoNorm(datingDataMat) inArr = array([ffMiles,percentTats,iceCream]) classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3) print"you will probably like this person: " + resultList[classifierResult - 1]