
我们为什么需要分布式,一方面是不得已而为之,例如
数据量太大,数据无法加载
模型太复杂,一个GPU放不下
或者我们也可以利用分布式提高我们的训练速度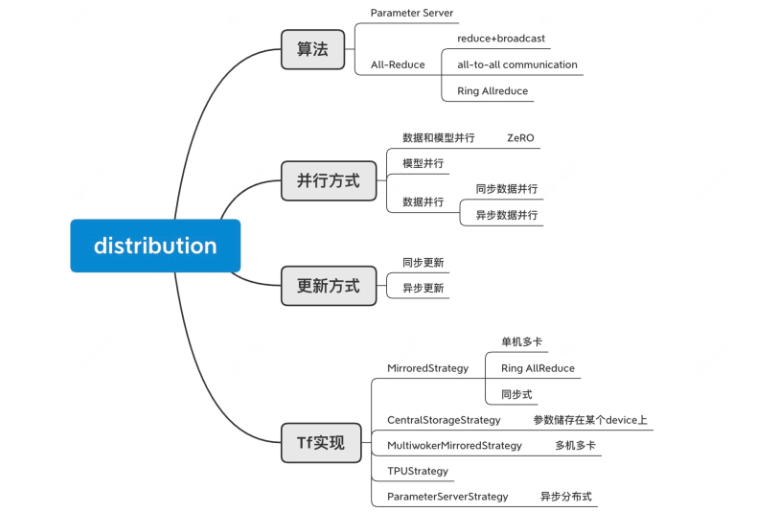
算法分类
Parameter Server
机器分为Parameter Server 和 woker 两类,Parameter server 负责整合梯度,更新参数,woker负责计算,训练网络。

从上图可以很清楚的看到PS的流程,共分为4步。
- Task Scheduler:
加载数据,并将数据分发给不同的workers - Workers:
1.计算梯度(1. compute)
加载训练数据; 从servers拉取最新的参数(4. Pull)
2.将梯度push到servers(2.Push)
从servers拉取最新的参数(4. Pull)
- Servers:
1.聚合梯度
2.更新参数(3. Update)
通信成本为: O(d/b(2m-1)), 通信时间和GPU个数成正比。
m: number of GPUs.
d: number of parameters.
b: network bandwidth.
Ring ALL-Reduce
reduce 和 all-reduce的区别:
- reduce:server 获取reduce之后的结果(sum/avg/mean/count),其他节点并不知道reduce之后的结果。例如我们需要进行reduce_sum 的操作,那么所有的workers的值都会传给server,然后server将这些值进行相加。

- all reduce:所有的节点都获取reduce之后的结果,不单单server有。all-reduce是reduce+broadcast。例如我们需要进行all-reduce_sum 的操作,那么所有的workers的值都会传给server,然后server将这些值进行相加,然后server会将相加的和broadcast给所有的workers。

- all-to-all communication。或者说如果没有 server 机器,那么我们可以通过all-to-all 通信,让每个节点都获取其他节点的值,然后再在各自机器上进行reduce。

首先我们有4台机器GPU 0:4, 我们的目标是将每个GPU计算出来的梯度 [公式] 进行相加,使得每个GPU都有所有GPU的梯度。
Ring All-Reduce
Native Approach
首先我们想到的方式是,我们将每个GPU的目前加和的梯度都向下传递,然后最后一个GPU可以得到最后的加和,然后它再将所有的结果传递给其他的没有获得结果的GPU。
整个过程如下:
- GPU0 将 g0 传给GPU1,GPU1得到 g0+g1 的结果

- GPU1 将 g0+g1 传给 GPU2,GPU2得到 g0+g1+g2 的结果

- GPU2 将 g0+g1+g2 传给 GPU3,GPU3得到 g0+g1+g2+g3 的结果

- GPU3 将 g=g0+g1+g2+g3 传给GPU0, GPU0 得到 g
- GPU0 将 g 传给GPU1, GPU1 得到 g
- GPU1 将 g 传给GPU3, GPU1 得到 g


最后每个worker自己做参数更新。
我们可以发现,这样子做的话,每次的数据传输都只用了一个通道,即只有两台GPU在进行传输,其他的3个通道都没有使用,造成了资源的浪费。
我们假设有 m 台机器,每台机器传输的参数量为 d, 传输带宽为 b, 我们可以得到传输的时间为 O(d*m/b),传输的速度和GPU数目成正比,这极大地限制了集群的可扩展性。
Ring All-Reduce (Efficient Approach)
为了充分利用起其他的通道,我们可以采取 Ring All-reduce的方式进行传输。其主要的作用就是将传输的时间不再正比于GPU的数目。
首先我们将传输的梯度进行 m 等分split,每一次的传输传的参数量为 d/m。 如下图。

首先我们得到GPU_i 计算出来的梯度倍等切成后的 gi=[ai;bi;ci;di](本例子为4等分),然后我们可以发现所有 ai 加起来是第一部分的加和,所有 bi 加起来是第2部分的加和,所有 ci 加起来是第3部分的加和,所有 di 加起来是第4部分的加和。并且 GPU0 可以传输给GPU1,GPU1 可以传输给GPU2,GPU2可以传输给GPU3,GPU3可以传输给GPU0,形成环状网络。
这个环状传输是同时进行的,其保证了每次传输的并行(纵向),且保证了每次的reduce计算都只在机器的一个部分,不会同一个机器多个部分同时进行(横向)。
- 首先进行第一次传输, GPU0 –a0–> GPU1,GPU1 –b1–> GPU2, GPU2 –c2–> GPU3, GPU3 –d3–> GPU0, 注意这边的初始传输值不是 a0, a1, a2,a3

- 第二次传输,就是将目前得到的每个部门的reduce结果,传输给下个device。
GPU1 –a0+a1–> GPU2,GPU2 –b1+b2–> GPU3, GPU3 –c2+c3–> GPU0, GPU0 –d0+d3–> GPU1
- 第三次传输,还是将上次传输的结果传给下一个device,注意这边传的是结果而不是中间过程,即例如传输 a0+a1+a2 是传输这个结果而不是三个a0,a1,a2参数,否则传输的参数量就增加了。
GPU2 –a0+a1+a2–> GPU3,GPU3 –b1+b2+b3–> GPU0, GPU0 –c0+c2+c3–> GPU1, GPU1 –d0+d1+d3–> GPU2
- 第四次传输,还是将上次传输的结果传给下一个device,此时,每个部分都已经有一个机器获得了最终的结果。

- 我们令a=a0+a1+a2+a3, b=b0+b1+b2+b3, c=c0+c1+c2+c3, d=d0+d1+d2+d3
GPU3 –a–> GPU0,GPU0 –b–> GPU1, GPU1 –d–> GPU2, GPU2 –d–> GPU3
- 第五次传输,如下

- 第六次传输

- 得到最终的结果:

我们可以计算一下时间的开销:O(d/m *m/b) = O(d/m) ,传输的时间和GPU的个数无关!
更新方式分类
同步式和异步式的区别在于参数的更新,是否需要等其他的worker的梯度计算完成。同步式需要,而异步式不需要。
同步式
我们以 MultiworkerMirroredStrategy 作为例子:
首先是数据并行,数据会被分发到不同的devices(下图的A/B/C)上,然后每个device 各自进行梯度计算,最后Parameter Device(s) 会等所有的梯度都计算完之后,再更新参数,最后将参数传给所有的devices。
同步式的更新的优缺点:
优点:
- 同步避免过多的通信(因为参数传输需要通信)
- 效果会比异步并行略好
缺点:
- 有的机器计算可能快,有的机器计算慢,这样就导致,个别机器会有计算资源的空耗,导致浪费。(单机多卡一般不会)

异步式
我们以 ParameterServerStrategy 作为例子:
首先我们的所有的数据还是进行并行化,分发到不同的devices(下图的A/B/C)上,每个 worker device 各自进行了梯度的计算后,传给parameter server,而参数服务器在收到了梯度之后,不用等其他机器的结果,直接去更新参数,得到新的参数值,传给各个worker。
异步式的更新的优缺点:
优点:
- 参数更新不需要等其他机器,所有更高效,避免短板效应(多机多卡)
- 异步的计算会增加模型的泛化能力,因为异步不是严格正确的,所以模型更容忍错误
缺点:
- 异步式更新的次数多了,会导致更多的通信时间
- 每个GPU计算完梯度后就各自更新,速度快,但是最终模型的性能略低于同步数据并行方式。

并行方式分类
数据并行
数据同时分发给各个worker,并进行梯度计算。
模型并行
当我们的模型过大,不能放在一个GPU中,那么需要将模型分成多个部分,在各个worker 中。
数据和模型并行
把数据和模型同时并行,进行训练。其中最出名的就是微软的ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters算法。它的出现使得训练超级大模型成了可能。微软用这个算法,训练出了 Turing-NLG: A 17-billion-parameter language model by Microsoft 170亿的参数,直接刷新世界观(壕无人性)

该ZeRO算法,主要如下图。

数据被分为n+1份,并行处理。
然后整个模型结构被过大,不能但在单一的GPU中,它被存放在n+1个GPU中,每个GPU存放三个部分
- 蓝色的部分是模型的参数
- 黄色的部分是模型的梯度
- 绿色的部分是模型梯度更新中间产生的数据,例如adam的中间产生数据。
那么模型要如何进行训练呢?
首先我们知道模型在进行更新的过程是先将数据正向传播,计算loss和梯度,再反向传播进行更新。例如下图,我们的模型存放在两个GPU中,在正向传播过程中我们必须等到数据经过GPU1,才能到GPU2,在反向传播过程中,我们需要保证GPU2的参数都计算完成,才能传到GPU1,这就导致了每次都有一个机器是闲置的。

这是因为我们的每个GPU都缺少了部分的模型参数,但是我们发现其实模型的参数并不大,大的是模型的 optimizer 的中间参数, 所以我们就是可以通过将所需要的其他部分的模型参数通过通信传输,获得,使得所有的部分都可以并行。
- 在进行前向传播的时候,我们以 GPU0 做为例子,在data0 flow的时候,如果需要任何的参数,都可以通过通信的过程获得,比如说刚开始先forward flow完成GPU0的模型结构,之后需要GPU1的模型结构,GPU1 会将其的参数传给GPU0,之后GPU2会将其的参数传给GPU0… 以此类推,直至前行传播完成获得loss。计算出梯度。注意此时DATA1,…DATAn+1 都在并行进行前向传播。
- 再反向传播的过程中,我们以 GPU0 做为例子,首先会计算出n+1 部分模型的梯度Gn+1(黄色的部分), GPU0 不会储存这个梯度,而是将它直接传输给GPU_{n+1}, 因为它负责更新n+1 部分模型(注意,此时所有的其他GPU计算出来的这部分的梯度都会传给它,最后在有它进行reduce),之后计算会计算出第n 部分模型的梯度Gn(黄色的部分),并传给 GPU_n,以此类推,算出得到第0部分模型的梯度G0(黄色的部分),然后并且收到了其他GPU关于此部分的梯度,并按照optimizer paramters进行第0部分的参数的更新。
引用
https://fyubang.com/2019/07/08/distributed-training/
https://zhuanlan.zhihu.com/p/129912419
https://www.youtube.com/watch%3Fv%3DtC01FRB0M7w

