
如何衡量翻译的好坏? 机器翻译越接近专业的人工翻译,它就越好。 这是我们的提议背后的核心理念。 为了判断机器翻译的质量,可以根据一个数值指标来衡量其与一个或多个人工参考翻译的接近程度。 因此,我们的MT评估系统需要两个成分:
- 一个“翻译接近度”数值指标
- 一个高质量的人工参考翻译语料库
BLEU(Bilingual Evaluation Understudy),相信大家对这个评价指标的概念已经很熟悉,随便百度谷歌就有相关介绍。原论文为BLEU: a Method for Automatic Evaluation of Machine Translation,IBM出品。
本文通过一个例子详细介绍BLEU是如何计算以及NLTK nltk.align.bleu_score模块的源码。
首先祭出公式:
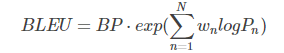
其中,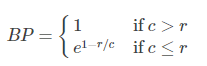
注意这里的BLEU值是针对一条翻译(一个样本)来说的。
NLTKnltk.align.bleu_score模块实现了这里的公式,主要包括三个函数,两个私有函数分别计算P和BP,一个函数整合计算BLEU值。
1 | # 计算BLEU值 |
例子
候选译文(Predicted):
It is a guide to action which ensures that the military always obeys the commands of the party
参考译文(Gold Standard)
1:It is a guide to action that ensures that the military will forever heed Party commands
2:It is the guiding principle which guarantees the military forces always being under the command of the Party
3:It is the practical guide for the army always to heed the directions of the party
Modified n-gram Precision计算(也即是Pn)
1 | def _modified_precision(candidate, references, n): |
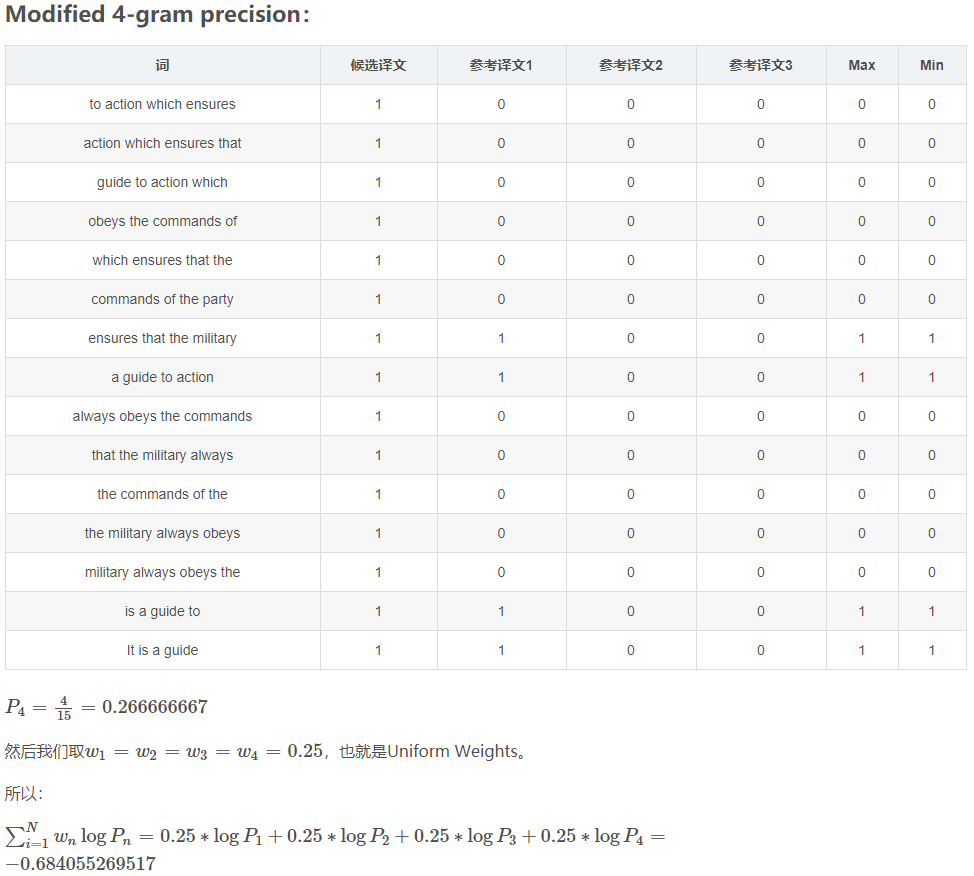
我们这里n取值为4,也就是从1-gram计算到4-gram。
Modified 1-gram precision
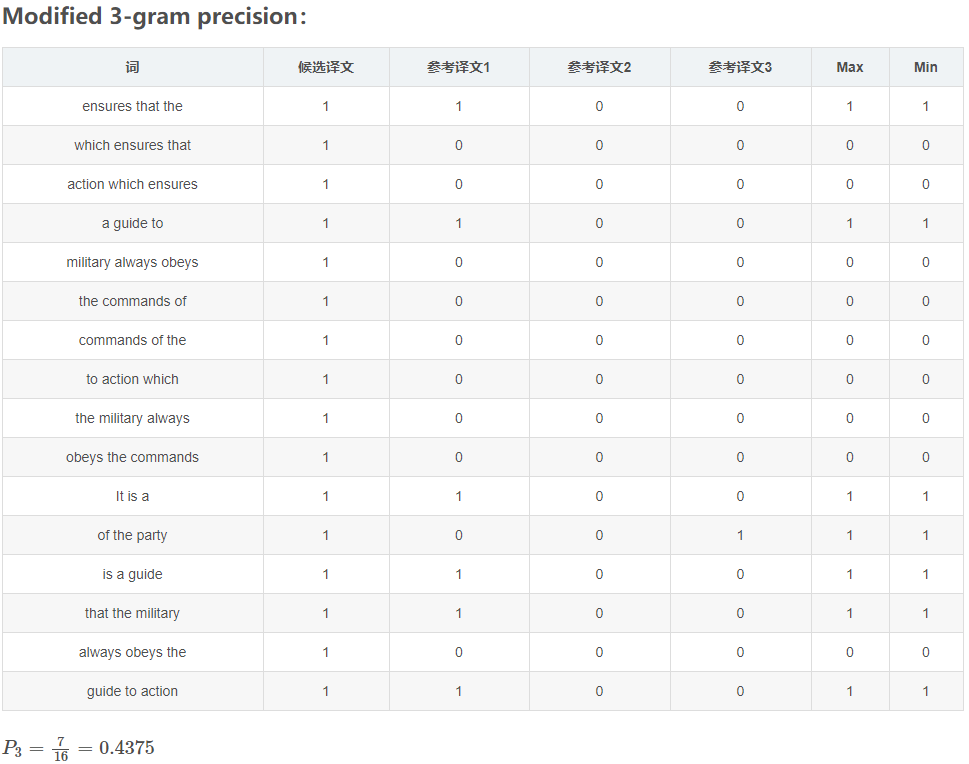
首先统计候选译文里每个词出现的次数,然后统计每个词在参考译文中出现的次数,Max表示3个参考译文中的最大值,Min表示候选译文和Max两个的最小值。
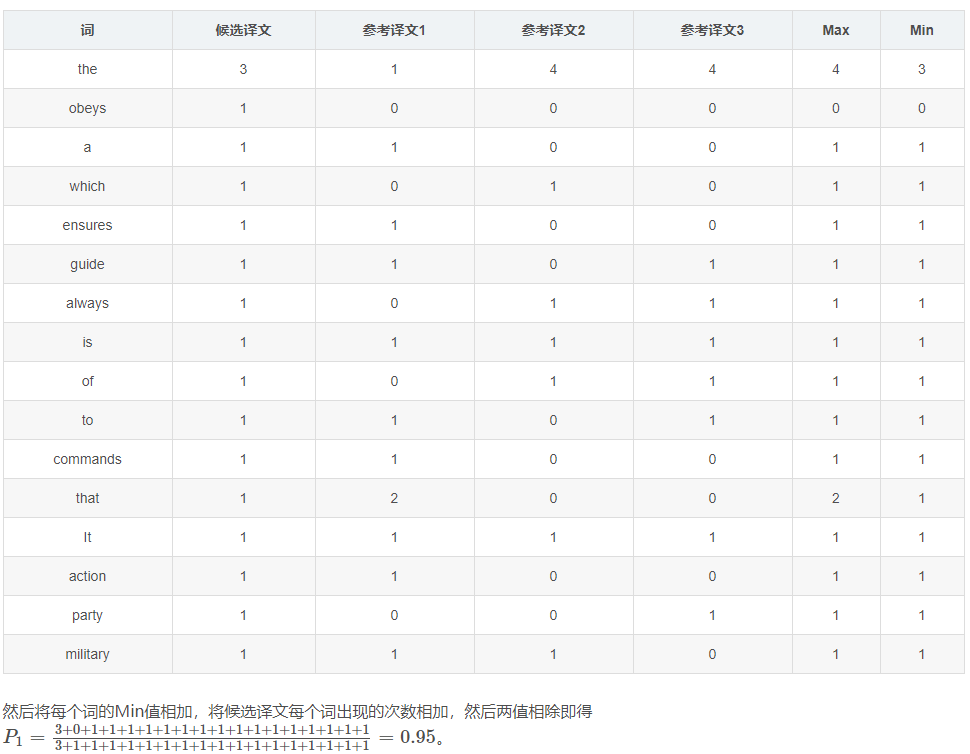
Modified 2-gram precision
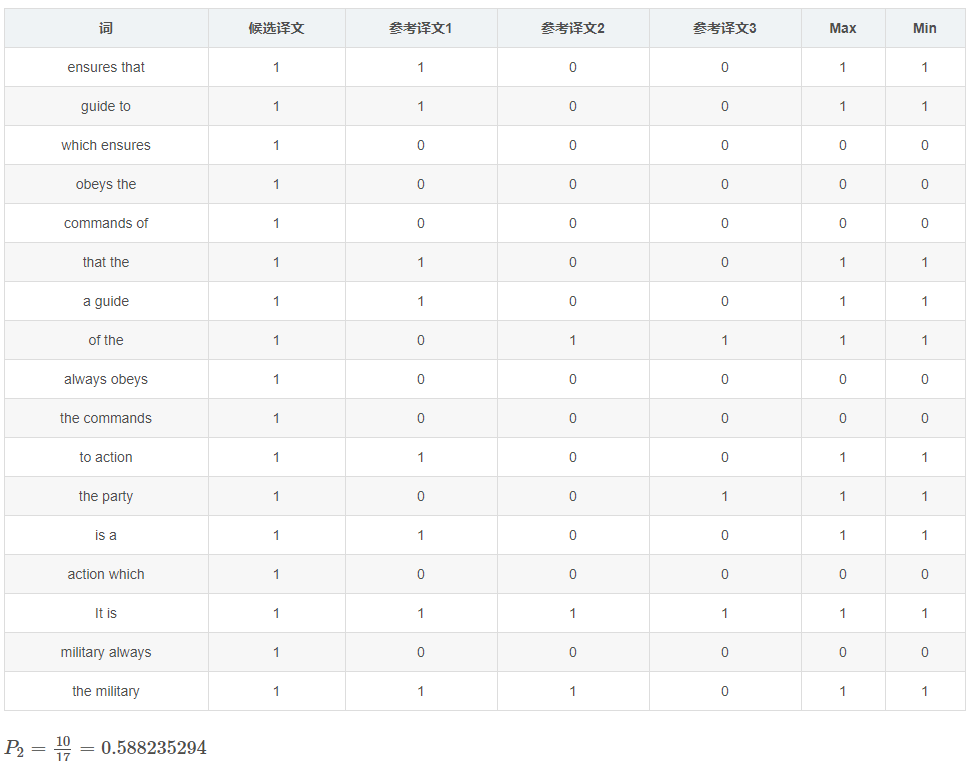
Modified 3-gram precision
Modified 4-gram precision
Brevity Penalty 计算
1 | def _brevity_penalty(candidate, references): |
下面计算BP(Brevity Penalty),翻译过来就是“过短惩罚”。由BP的公式可知取值范围是(0,1],候选句子越短,越接近0。
候选翻译句子长度为18,参考翻译分别为:16,18,16。
所以c = 18,r=18(参考翻译中选取长度最接近候选翻译的作为rr)
所以BP = e^0 =1
整合
最终BLEU = 1 ⋅ exp(−0.684055269517) = 0.504566684006
BLEU的取值范围是[0,1],0最差,1最好。
通过计算过程,我们可以看到,BLEU值其实也就是“改进版的n-gram”加上“过短惩罚因子”。
参考:
https://link.zhihu.com/?target=https%3A//www.yiyibooks.cn/yiyibooks/BLEU_a_Method_for_Automatic_Evaluation_of_Machine_Translation/index.html
https://blog.csdn.net/guolindonggld/java/article/details/56966200
https://www.zhihu.com/question/304798594/answer/567383628

